Legendaryry
現在、コンテンツはありません
Legendaryry
Asked GPT Image 2.0 to create a benchmark table of opus 4.7 vs gpt 5.5.
その画像モデルは非常に良くなった。
GPT-5.5がヘッドラインのスコアボードで勝利した。でもよく見てみて。
OSWorld 78.7対78.0。GDPval 84.9対80.3。Toolathlon 55.6対54.6 (オーバー5.4、Opusではなく)。
OpusはまだSWE-Bench Pro、MCP Atlas、GPQA Diamond、HLE no-toolsを使用している。
OpenAIはオールラウンドのベルトを獲得。Anthropicはコーディングの王冠を維持。紙の上では。
原文表示その画像モデルは非常に良くなった。
GPT-5.5がヘッドラインのスコアボードで勝利した。でもよく見てみて。
OSWorld 78.7対78.0。GDPval 84.9対80.3。Toolathlon 55.6対54.6 (オーバー5.4、Opusではなく)。
OpusはまだSWE-Bench Pro、MCP Atlas、GPQA Diamond、HLE no-toolsを使用している。
OpenAIはオールラウンドのベルトを獲得。Anthropicはコーディングの王冠を維持。紙の上では。

- 報酬
- いいね
- コメント
- リポスト
- 共有
- 報酬
- いいね
- コメント
- リポスト
- 共有
- 報酬
- いいね
- コメント
- リポスト
- 共有

ティム・クック、AppleのCEOを辞任
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
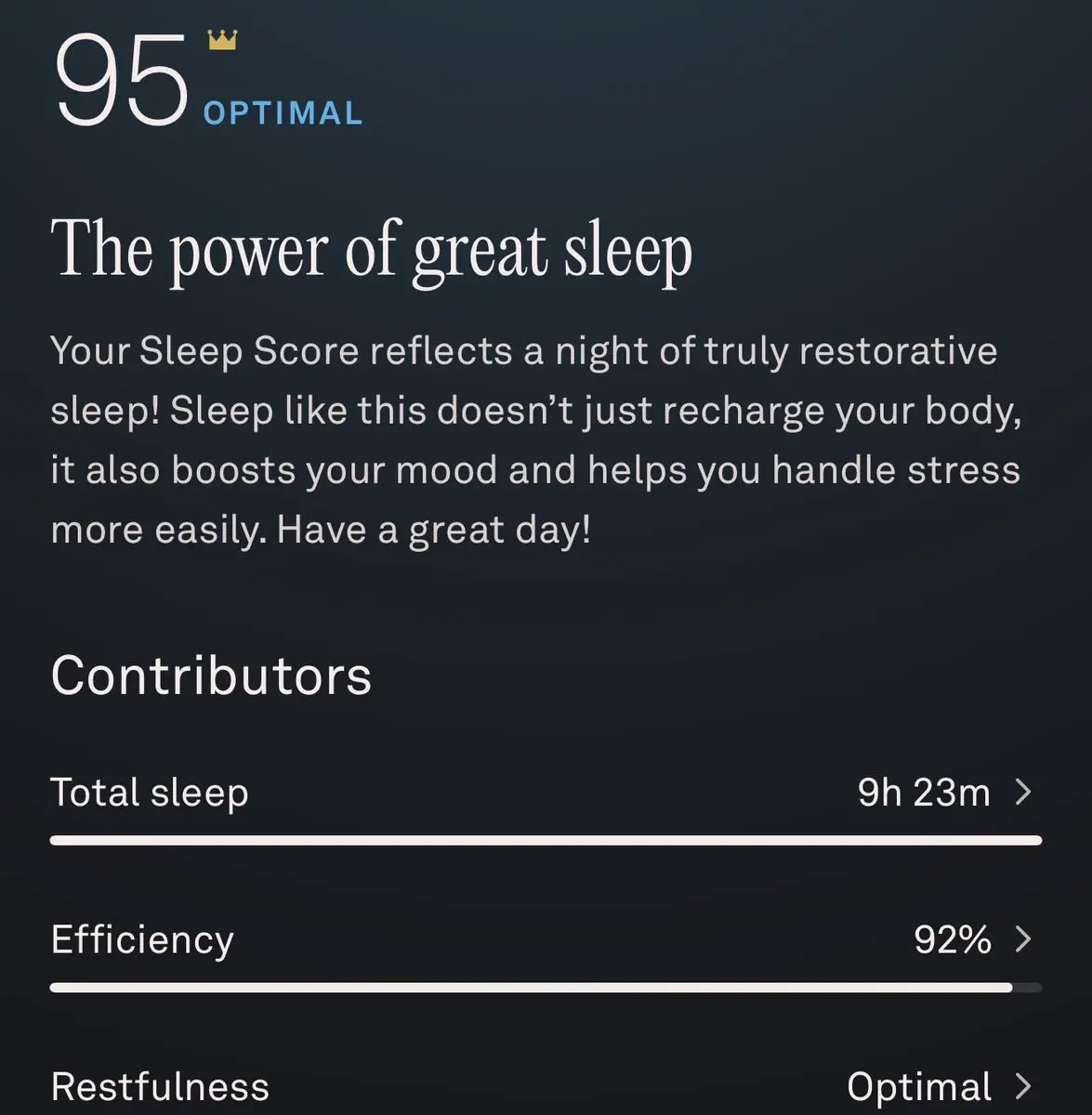
私は先週、ヨーロッパからニューヨーク市へ旅行して、8.5時間の悪い睡眠負債を抱えました。
帰宅初日には9.5時間眠ったのに、準備完了スコアはまだ追いついていません。
旅行と健康最大化は本当に難しいです。
原文表示帰宅初日には9.5時間眠ったのに、準備完了スコアはまだ追いついていません。
旅行と健康最大化は本当に難しいです。
- 報酬
- いいね
- コメント
- リポスト
- 共有
ケルプDAOが悪用される、DeFiは終わったのか
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
rip defi (2020-2026)
defiは焼かれており、mythosは公開アクセス可能なLLMですらありません。
オンチェーンの利回りが現実世界の利回りとほとんど変わらないのに、リスクは何倍も大きいため、レートに参加する正当性を見出すのは難しい。
原文表示defiは焼かれており、mythosは公開アクセス可能なLLMですらありません。
オンチェーンの利回りが現実世界の利回りとほとんど変わらないのに、リスクは何倍も大きいため、レートに参加する正当性を見出すのは難しい。
- 報酬
- いいね
- コメント
- リポスト
- 共有
OpenClawからHermesに切り替えた皆さんは調子はいかがですか?
振り返ってみましたか?Hermesに満足していますか、それとも両方同時に運用していますか?
原文表示振り返ってみましたか?Hermesに満足していますか、それとも両方同時に運用していますか?
- 報酬
- いいね
- コメント
- リポスト
- 共有
ニューヨーク市でグレーディング済みのポケモンスカイリッジを購入するのに良い場所はどこですか?
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有

S&P 500が初めて7,000を上回る
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
なぜ皆突然戦略のSTRCを買い始めたのか
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
- 報酬
- いいね
- コメント
- リポスト
- 共有
トランプ大統領の海軍封鎖が原油価格を上昇させ、株価を下落させる
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
アントロピックは最近、クロードに20時間の精神科セッションを受けさせた。本物の精神科医によるもので、4〜6時間のブロックを複数回行い、「コアコンフリクト」や「本物の自己状態と演技的な自己状態」についての書面レポートを作成した。
一方、認定されたカウンセラーはx402エンドポイントを提供し、どのAIエージェントも$110 USDCをベース上で支払い、自分自身のカウンセリングセッションを予約できるようにした。ケースは同じリクエストで提出され、回答は24時間以内に得られる。インテーク項目には「エージェントの葛藤」や「オペレーターのダイナミクス」が含まれる。
アントロピックは自社の臨床医を雇用して一つのモデルに対してこれを行っているが、市場はただちにこれを$110 セッションの価格に設定した。
エージェント福祉経済はもはや予測ではなく、価格ページになった。
一方、認定されたカウンセラーはx402エンドポイントを提供し、どのAIエージェントも$110 USDCをベース上で支払い、自分自身のカウンセリングセッションを予約できるようにした。ケースは同じリクエストで提出され、回答は24時間以内に得られる。インテーク項目には「エージェントの葛藤」や「オペレーターのダイナミクス」が含まれる。
アントロピックは自社の臨床医を雇用して一つのモデルに対してこれを行っているが、市場はただちにこれを$110 セッションの価格に設定した。
エージェント福祉経済はもはや予測ではなく、価格ページになった。
原文表示
- 報酬
- いいね
- コメント
- リポスト
- 共有
人気の話題
もっと見る1.12M 人気度
831.54K 人気度
30.82K 人気度
201.38K 人気度
76.52K 人気度
ピン