ที่มา: Qubit
ความสำเร็จล่าสุดของทีมของ Li Feifei หน่วยสืบราชการลับที่เป็นตัวเป็นตน อยู่ที่นี่:
โมเดลขนาดใหญ่เชื่อมต่อกับหุ่นยนต์เพื่อแปลงคำสั่งที่ซับซ้อนให้เป็นแผนปฏิบัติการเฉพาะโดยไม่ต้องใช้ข้อมูลและการฝึกอบรมเพิ่มเติม
 จากนั้นเป็นต้นมา มนุษย์สามารถใช้ภาษาธรรมชาติเพื่อสั่งการหุ่นยนต์ได้อย่างอิสระ เช่น:
จากนั้นเป็นต้นมา มนุษย์สามารถใช้ภาษาธรรมชาติเพื่อสั่งการหุ่นยนต์ได้อย่างอิสระ เช่น:
เปิดลิ้นชักด้านบนแล้วระวังแจกัน!
 แบบจำลองภาษาขนาดใหญ่ + แบบจำลองภาษาภาพสามารถวิเคราะห์เป้าหมายและอุปสรรคที่ต้องข้ามจากพื้นที่ 3 มิติ ช่วยให้หุ่นยนต์สามารถวางแผนการดำเนินการได้
แบบจำลองภาษาขนาดใหญ่ + แบบจำลองภาษาภาพสามารถวิเคราะห์เป้าหมายและอุปสรรคที่ต้องข้ามจากพื้นที่ 3 มิติ ช่วยให้หุ่นยนต์สามารถวางแผนการดำเนินการได้
 ประเด็นสำคัญก็คือหุ่นยนต์ใน โลกแห่งความจริง สามารถทำงานนี้ได้โดยตรงโดยไม่ต้อง “ฝึกฝน”
ประเด็นสำคัญก็คือหุ่นยนต์ใน โลกแห่งความจริง สามารถทำงานนี้ได้โดยตรงโดยไม่ต้อง “ฝึกฝน”
 วิธีการใหม่นี้ทำให้การสังเคราะห์เส้นทางการเคลื่อนที่ของการปฏิบัติงานประจำวันกลายเป็นศูนย์ตัวอย่าง นั่นคือ งานที่หุ่นยนต์ไม่เคยเห็นมาก่อนสามารถดำเนินการได้ในคราวเดียว โดยไม่ต้องสาธิตด้วยซ้ำ
วิธีการใหม่นี้ทำให้การสังเคราะห์เส้นทางการเคลื่อนที่ของการปฏิบัติงานประจำวันกลายเป็นศูนย์ตัวอย่าง นั่นคือ งานที่หุ่นยนต์ไม่เคยเห็นมาก่อนสามารถดำเนินการได้ในคราวเดียว โดยไม่ต้องสาธิตด้วยซ้ำ
วัตถุที่ใช้งานได้ยังเปิดอยู่ คุณไม่จำเป็นต้องกำหนดขอบเขตล่วงหน้า คุณสามารถเปิดขวด กดสวิตช์ และถอดสายชาร์จออกได้
 ในปัจจุบัน หน้าแรกของโครงการและเอกสารต่างๆ เป็นแบบออนไลน์ และจะมีการเผยแพร่โค้ดเร็วๆ นี้ และกระตุ้นความสนใจอย่างกว้างขวางในชุมชนวิชาการ
ในปัจจุบัน หน้าแรกของโครงการและเอกสารต่างๆ เป็นแบบออนไลน์ และจะมีการเผยแพร่โค้ดเร็วๆ นี้ และกระตุ้นความสนใจอย่างกว้างขวางในชุมชนวิชาการ
 อดีตนักวิจัยของไมโครซอฟต์ให้ความเห็นว่า: การวิจัยนี้อยู่ที่พรมแดนที่สำคัญและซับซ้อนที่สุดของระบบปัญญาประดิษฐ์
อดีตนักวิจัยของไมโครซอฟต์ให้ความเห็นว่า: การวิจัยนี้อยู่ที่พรมแดนที่สำคัญและซับซ้อนที่สุดของระบบปัญญาประดิษฐ์
 โดยเฉพาะอย่างยิ่งสำหรับชุมชนการวิจัยหุ่นยนต์ เพื่อนร่วมงานบางคนกล่าวว่าได้เปิดโลกใหม่สำหรับด้านการวางแผนการเคลื่อนไหว
โดยเฉพาะอย่างยิ่งสำหรับชุมชนการวิจัยหุ่นยนต์ เพื่อนร่วมงานบางคนกล่าวว่าได้เปิดโลกใหม่สำหรับด้านการวางแผนการเคลื่อนไหว
 ยังมีคนที่ไม่เห็นอันตรายของ AI แต่เนื่องจากการวิจัยเกี่ยวกับ AI ร่วมกับหุ่นยนต์ทำให้พวกเขาเปลี่ยนมุมมอง
ยังมีคนที่ไม่เห็นอันตรายของ AI แต่เนื่องจากการวิจัยเกี่ยวกับ AI ร่วมกับหุ่นยนต์ทำให้พวกเขาเปลี่ยนมุมมอง

**หุ่นยนต์เข้าใจคำพูดของมนุษย์โดยตรงได้อย่างไร? **
ทีมงานของ Li Feifei ตั้งชื่อระบบว่า VoxPoser ดังแสดงในรูปด้านล่าง หลักการง่ายมาก
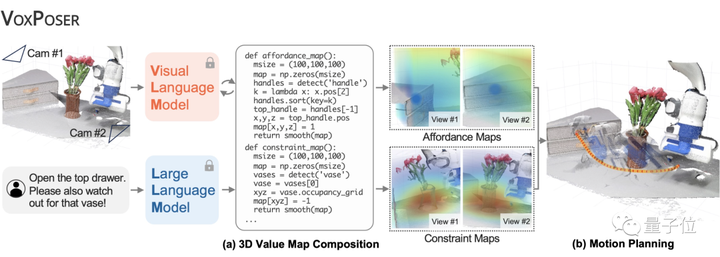 ขั้นแรก ให้ข้อมูลเกี่ยวกับสภาพแวดล้อม (เก็บภาพ RGB-D ด้วยกล้อง) และคำสั่งภาษาธรรมชาติที่เราต้องการดำเนินการ
ขั้นแรก ให้ข้อมูลเกี่ยวกับสภาพแวดล้อม (เก็บภาพ RGB-D ด้วยกล้อง) และคำสั่งภาษาธรรมชาติที่เราต้องการดำเนินการ
จากนั้น LLM (Large Language Model) จะเขียนโค้ดตามเนื้อหาเหล่านี้ และโค้ดที่สร้างขึ้นจะโต้ตอบกับ VLM (Visual Language Model) เพื่อเป็นแนวทางให้ระบบสร้างแผนผังคำแนะนำการดำเนินการที่เกี่ยวข้อง ซึ่งก็คือ 3D Value Map
 สิ่งที่เรียกว่าแผนที่มูลค่า 3 มิติ ซึ่งเป็นคำทั่วไปสำหรับ Affordance Map และ Constraint Map ทำเครื่องหมายทั้ง “ตำแหน่งที่ต้องดำเนินการ” และ “วิธีดำเนินการ”**
สิ่งที่เรียกว่าแผนที่มูลค่า 3 มิติ ซึ่งเป็นคำทั่วไปสำหรับ Affordance Map และ Constraint Map ทำเครื่องหมายทั้ง “ตำแหน่งที่ต้องดำเนินการ” และ “วิธีดำเนินการ”**
 ด้วยวิธีนี้ ตัววางแผนการดำเนินการจะถูกย้ายออกไป และแผนที่ 3 มิติที่สร้างขึ้นจะถูกใช้เป็นฟังก์ชันวัตถุประสงค์เพื่อสังเคราะห์แนวทางการดำเนินการขั้นสุดท้ายที่จะดำเนินการ
ด้วยวิธีนี้ ตัววางแผนการดำเนินการจะถูกย้ายออกไป และแผนที่ 3 มิติที่สร้างขึ้นจะถูกใช้เป็นฟังก์ชันวัตถุประสงค์เพื่อสังเคราะห์แนวทางการดำเนินการขั้นสุดท้ายที่จะดำเนินการ
จากขั้นตอนนี้ เราจะเห็นว่าเมื่อเทียบกับวิธีดั้งเดิมแล้ว จำเป็นต้องมีการฝึกอบรมล่วงหน้าเพิ่มเติม วิธีนี้ใช้แบบจำลองขนาดใหญ่เพื่อแนะนำหุ่นยนต์ถึงวิธีการโต้ตอบกับสิ่งแวดล้อม ดังนั้นจึงแก้ปัญหาการขาดแคลนข้อมูลการฝึกอบรมหุ่นยนต์ได้โดยตรง .
ยิ่งกว่านั้น เป็นเพราะคุณสมบัตินี้ที่ทำให้ตระหนักถึงความสามารถของ Zero-sample ตราบใดที่กระบวนการพื้นฐานข้างต้นได้รับการฝึกฝนจนเชี่ยวชาญ
ในการใช้งานที่เฉพาะเจาะจง ผู้เขียนเปลี่ยนแนวคิดของ VoxPoser ให้เป็นปัญหาการเพิ่มประสิทธิภาพ นั่นคือ สูตรที่ซับซ้อนต่อไปนี้:
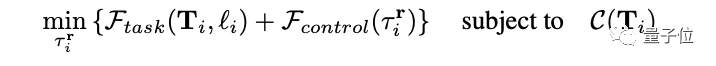 โดยคำนึงว่าคำสั่งที่มนุษย์มอบให้อาจมีหลากหลายและต้องการความเข้าใจตามบริบท ดังนั้น คำสั่งจึงแยกย่อยออกเป็นหลายงานย่อย ตัวอย่างเช่น ตัวอย่างแรกในตอนเริ่มต้นประกอบด้วย “คว้าที่จับ ลิ้นชัก” และ “ดึง ลิ้นชัก”.
โดยคำนึงว่าคำสั่งที่มนุษย์มอบให้อาจมีหลากหลายและต้องการความเข้าใจตามบริบท ดังนั้น คำสั่งจึงแยกย่อยออกเป็นหลายงานย่อย ตัวอย่างเช่น ตัวอย่างแรกในตอนเริ่มต้นประกอบด้วย “คว้าที่จับ ลิ้นชัก” และ “ดึง ลิ้นชัก”.
สิ่งที่ VoxPoser ต้องการบรรลุคือเพิ่มประสิทธิภาพงานย่อยแต่ละงาน รับชุดเส้นทางการเคลื่อนที่ของหุ่นยนต์ และลดภาระงานทั้งหมดและเวลาในการทำงานให้เหลือน้อยที่สุด
ในกระบวนการใช้ LLM และ VLM เพื่อแมปคำสั่งภาษาลงในแผนที่ 3 มิติ ระบบจะพิจารณาว่าภาษานั้นสามารถถ่ายทอดพื้นที่ความหมายที่หลากหลายได้ ดังนั้นจึงใช้ “เอนทิตีของความสนใจ(เอนทิตีของความสนใจ)” เพื่อนำทางหุ่นยนต์ไปยัง ดำเนินการ นั่นคือผ่านค่าที่ทำเครื่องหมายในแผนที่ 3DValue เพื่อสะท้อนว่าวัตถุใด “น่าดึงดูด” สำหรับวัตถุนั้น และวัตถุเหล่านั้น “น่ารังเกียจ”
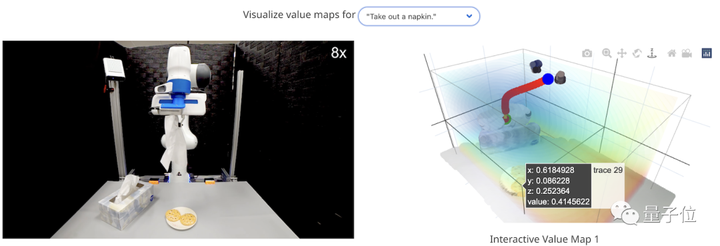 ยังคงใช้ตัวอย่างในตอนเริ่มต้น 🌰 ลิ้นชักคือ “ดึงดูด” และแจกันคือ “ขับไล่”
ยังคงใช้ตัวอย่างในตอนเริ่มต้น 🌰 ลิ้นชักคือ “ดึงดูด” และแจกันคือ “ขับไล่”
แน่นอนว่าวิธีสร้างค่าเหล่านี้ขึ้นอยู่กับความสามารถในการทำความเข้าใจของโมเดลภาษาขนาดใหญ่
ในกระบวนการสังเคราะห์วิถีสุดท้ายเนื่องจากเอาต์พุตของโมเดลภาษาคงที่ตลอดงานเราจึงสามารถประเมินใหม่ได้อย่างรวดเร็วเมื่อพบการรบกวนโดยแคชเอาต์พุตและประเมินรหัสที่สร้างขึ้นใหม่โดยใช้การตอบสนองด้วยภาพวงปิด การวางแผน
ดังนั้น VoxPoser จึงมีความสามารถในการป้องกันการรบกวนที่แข็งแกร่ง
 △ ใส่เศษกระดาษลงในถาดสีน้ำเงิน
△ ใส่เศษกระดาษลงในถาดสีน้ำเงิน
ต่อไปนี้เป็นประสิทธิภาพของ VoxPoser ในสภาพแวดล้อมจริงและจำลอง (วัดจากอัตราความสำเร็จเฉลี่ย):
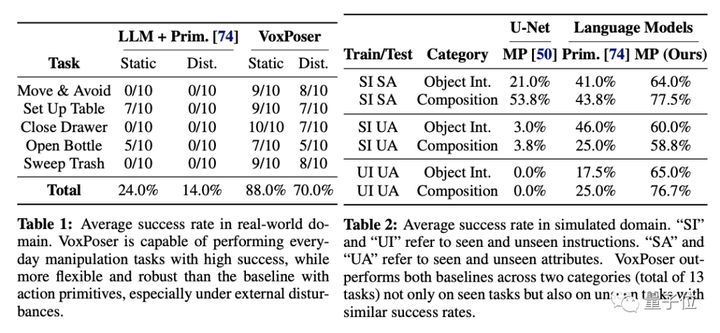 จะเห็นได้ว่างานนั้นสูงกว่างานพื้นฐานพื้นฐานดั้งเดิมอย่างเห็นได้ชัดโดยไม่คำนึงถึงสภาพแวดล้อม (โดยมีหรือไม่มีตัวรบกวน ไม่ว่าคำแนะนำจะมองเห็นหรือไม่ก็ตาม)
จะเห็นได้ว่างานนั้นสูงกว่างานพื้นฐานพื้นฐานดั้งเดิมอย่างเห็นได้ชัดโดยไม่คำนึงถึงสภาพแวดล้อม (โดยมีหรือไม่มีตัวรบกวน ไม่ว่าคำแนะนำจะมองเห็นหรือไม่ก็ตาม)
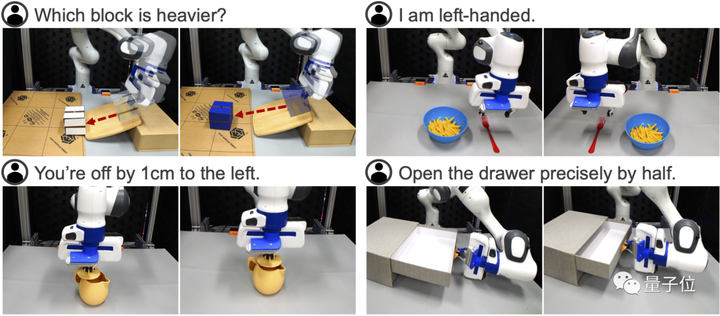
ในที่สุด ผู้เขียนรู้สึกประหลาดใจอย่างยิ่งที่พบว่า VoxPoser ผลิต 4 “ความสามารถฉุกเฉิน”:
(1) ประเมินลักษณะทางกายภาพ เช่น ให้บล็อกไม่ทราบมวล 2 บล็อก ให้หุ่นยนต์ใช้เครื่องมือทำการทดลองทางกายภาพเพื่อดูว่าบล็อกใดหนักกว่า
(2) การให้เหตุผลตามสามัญสำนึกเชิงพฤติกรรม เช่น ในงานวางภาชนะบนโต๊ะอาหาร ให้บอกหุ่นยนต์ว่า “ฉันถนัดซ้าย” และหุ่นยนต์สามารถเข้าใจความหมายผ่านบริบท
(3) การแก้ไขแบบละเอียด ตัวอย่างเช่น เมื่อทำงานที่ต้องการความแม่นยำสูง เช่น “ปิดกาน้ำชา” เราสามารถออกคำสั่งที่แม่นยำให้กับหุ่นยนต์ เช่น “คุณเบี่ยงเบนไป 1 ซม.” เพื่อแก้ไขการทำงาน
(4) การทำงานหลายขั้นตอนตามการมองเห็น เช่น การขอให้หุ่นยนต์เปิดลิ้นชักครึ่งหนึ่งอย่างถูกต้อง การขาดข้อมูล เนื่องจากไม่มีแบบจำลองวัตถุอาจทำให้หุ่นยนต์ไม่สามารถทำงานดังกล่าวได้ แต่ VoxPoser สามารถเสนอ กลยุทธ์การทำงานแบบหลายขั้นตอนตามการตอบสนองด้วยภาพ กล่าวคือ ขั้นแรกให้เปิดลิ้นชักจนสุดในขณะที่บันทึกการเคลื่อนตัวของที่จับ จากนั้น ดันกลับไปที่จุดกึ่งกลางเพื่อให้เป็นไปตามข้อกำหนด
เฟย-เฟยลี่: 3 ดาวเหนือแห่งคอมพิวเตอร์วิชั่น
เมื่อประมาณหนึ่งปีที่แล้ว Li Feifei เขียนบทความลงใน Journal of the American Academy of Arts and Sciences โดยชี้ให้เห็นสามทิศทางในการพัฒนาการมองเห็นของคอมพิวเตอร์:
- เป็นตัวเป็นตน AI
- การให้เหตุผลด้วยภาพ
- ความเข้าใจฉาก
 Li Feifei เชื่อว่าหน่วยสืบราชการลับในร่างไม่ได้หมายถึงหุ่นยนต์คล้ายมนุษย์เท่านั้น แต่เครื่องจักรอัจฉริยะที่จับต้องได้ที่สามารถเคลื่อนที่ในอวกาศได้ถือเป็นรูปแบบหนึ่งของปัญญาประดิษฐ์
Li Feifei เชื่อว่าหน่วยสืบราชการลับในร่างไม่ได้หมายถึงหุ่นยนต์คล้ายมนุษย์เท่านั้น แต่เครื่องจักรอัจฉริยะที่จับต้องได้ที่สามารถเคลื่อนที่ในอวกาศได้ถือเป็นรูปแบบหนึ่งของปัญญาประดิษฐ์
เช่นเดียวกับที่ ImageNet ตั้งเป้าที่จะนำเสนอภาพในโลกแห่งความเป็นจริงที่หลากหลาย ดังนั้นการวิจัยข่าวกรองที่เป็นตัวเป็นตนจึงจำเป็นต้องจัดการกับงานที่ซับซ้อนและหลากหลายของมนุษย์ ตั้งแต่การพับผ้าไปจนถึงการสำรวจเมืองใหม่ๆ
การปฏิบัติตามคำแนะนำเพื่อทำงานเหล่านี้ต้องใช้การมองเห็น แต่ไม่ใช่แค่การมองเห็นเท่านั้น แต่ยังต้องใช้เหตุผลทางภาพเพื่อทำความเข้าใจความสัมพันธ์สามมิติในฉาก
ประการสุดท้าย เครื่องจักรต้องเข้าใจผู้คนในฉาก รวมถึงความตั้งใจของมนุษย์และความสัมพันธ์ทางสังคม เช่น เห็นคนเปิดตู้เย็นก็บอกได้ว่าหิว หรือเห็นเด็กนั่งตักผู้ใหญ่ก็บอกได้ว่าเป็นพ่อแม่ลูก
หุ่นยนต์รวมกับโมเดลขนาดใหญ่อาจเป็นเพียงวิธีหนึ่งในการแก้ปัญหาเหล่านี้
 นอกจาก Li Feifei แล้ว ศิษย์เก่าของ Tsinghua Yaoban Wu Jiajun ซึ่งสำเร็จการศึกษาระดับปริญญาเอกจาก MIT และปัจจุบันเป็นผู้ช่วยศาสตราจารย์ที่ Stanford University ได้เข้าร่วมในงานวิจัยนี้ด้วย
นอกจาก Li Feifei แล้ว ศิษย์เก่าของ Tsinghua Yaoban Wu Jiajun ซึ่งสำเร็จการศึกษาระดับปริญญาเอกจาก MIT และปัจจุบันเป็นผู้ช่วยศาสตราจารย์ที่ Stanford University ได้เข้าร่วมในงานวิจัยนี้ด้วย
 ผู้เขียนวิทยานิพนธ์คนแรก Wenlong Huang ปัจจุบันเป็นนักศึกษาปริญญาเอกที่ Stanford และเข้าร่วมการวิจัย PaLM-E ระหว่างฝึกงานที่ Google
ผู้เขียนวิทยานิพนธ์คนแรก Wenlong Huang ปัจจุบันเป็นนักศึกษาปริญญาเอกที่ Stanford และเข้าร่วมการวิจัย PaLM-E ระหว่างฝึกงานที่ Google
 ที่อยู่กระดาษ:
หน้าแรกของโครงการ:
ลิงค์อ้างอิง:
[1]
[1]
ที่อยู่กระดาษ:
หน้าแรกของโครงการ:
ลิงค์อ้างอิง:
[1]
[1]
