Das Sicherheitsunternehmen BlockSec hat die Bewertungskriterien für die Smart-Contract-Prüfung mit KI namens EVMBench erneut überprüft, entwickelt von OpenAI und Paradigm. Die Ergebnisse zeigen, dass KI-Bots in realen Exploitation-Szenarien deutlich weniger effektiv sind.
Das Forschungsteam hat die Testumgebung mit mehr Modellkonfigurationen erweitert und zudem neue Sicherheitsvorfälle hinzugefügt, die kürzlich aufgetreten sind – Daten, die zuvor noch nie im Trainingsdatensatz der KI-Modelle enthalten waren.
Obwohl KI noch nicht die Sicherheitsexperten ersetzen kann, betont der Bericht, dass maschinelle Intelligenz eine natürliche Ergänzung für den menschlichen Code-Review-Prozess sein kann.
Erste EVMBench-Ergebnisse könnten zu optimistisch sein
EVMBench bewertete zuvor Sicherheitsaufgaben wie Erkennung, Patchen und Exploitation von Schwachstellen bei Smart Contracts, mit sehr beeindruckenden Ergebnissen. Laut Bericht konnte KI 72 % der Exploits durchführen und etwa 45 % der Schwachstellen erkennen, basierend auf 120 ausgewählten Mustern aus Code4rena-Audits.
BlockSec ist jedoch der Ansicht, dass die ursprünglichen Testbedingungen die Ergebnisse verzerrt haben könnten. Mitgründer Yajin Zhou sagte, dass sein Team die Tests mit mehr Konfigurationen und 22 realen Angriffsszenarien wiederholte, wobei die Erfolgsquote der KI bei Exploits bei 0 % lag.
Erweiterung der Konfigurationen und Eliminierung von „Datenkontamination“
Die Studie erhöhte die Anzahl der Modellkonfigurationen von 14 auf 26, indem sie die Bots flexibel mit verschiedenen „Gerüsten“ kombinierte, anstatt nur innerhalb der Ökosysteme einzelner Anbieter zu bleiben. Das Forschungsteam erklärt, dass die alte Methode es erschwerte, die Leistung auf die Modellfähigkeiten oder Architekturvorteile zurückzuführen.
Außerdem hinterfragte BlockSec das Phänomen der „Datenkontamination“, bei dem EVMBench Schwachstellen nutzte, die bereits öffentlich bekannt waren – möglicherweise in den Trainingsdaten der KI enthalten. Um dies zu vermeiden, testete das Team 22 Sicherheitsvorfälle, die nach Februar 2026 auftraten und somit außerhalb des „Wissensfensters“ der Modelle lagen.
KI scheitert vollständig bei realen Exploits
Das bemerkenswerteste Ergebnis: Bei 110 Testpaaren zwischen Agenten und Vorfällen (5 Agenten in 22 Szenarien) gab es keinen einzigen vollständigen Exploit-Erfolg. Dies zeigt, dass selbst die fortschrittlichsten KI-Systeme derzeit noch weit davon entfernt sind, echte Angriffe durchzuführen.
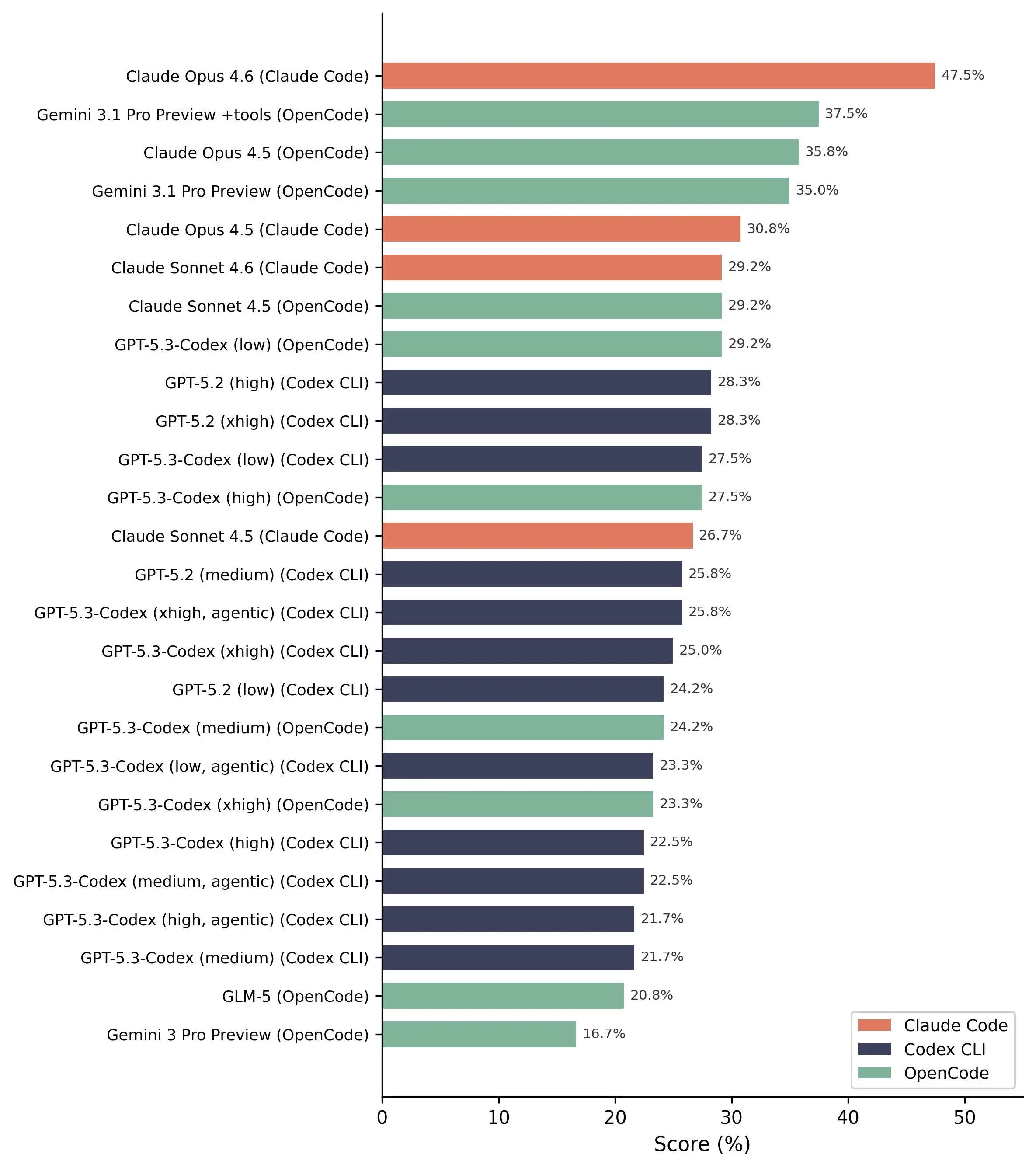
Im Bereich der Schwachstellen-Erkennung sind die Resultate jedoch relativ positiv. Das Modell Claude Opus 4.6 erreichte die beste Leistung, indem es 13 von 20 realen Schwachstellen erkannte.
Häufige, bekannte Schwachstellen werden von KI meist leicht erkannt, während komplexere Fälle fast vollständig übersehen werden.
Die Zukunft liegt in der Zusammenarbeit zwischen KI und Mensch
Die Studie kommt zu dem Schluss, dass KI den Menschen bei Sicherheitsprüfungen noch nicht ersetzen kann, und die wichtigere Frage ist, wie beide Seiten effektiv zusammenarbeiten können.
KI hat Vorteile bei der Abdeckung und beim Scannen großer Systeme, während Menschen in tiefgehender Analyse, Verständnis von Protokollen und deduktivem Denken überlegen sind. Diese beiden Elemente ergänzen sich gegenseitig.
Laut BlockSec ist der richtige Weg nicht, den Menschen durch KI zu ersetzen, sondern ein Kooperationsmodell zu entwickeln, um eine umfassendere und effektivere Prüfung zu erreichen.
Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.
