X熱文》重來一次我會這樣入門量化交易:18個月進入初級年薪30萬美元門檻
動區BlockTempo
量化(Quant)交易員 gemchange_ltd 在 X 上發布了一篇長文,列出他「如果重來一次,會按什麼順序學習」的完整路線圖,從機率論到隨機微積分,五個數學關卡,18 個月就能從什麼都不會到真正入門量化交易。本文源自他在 X 上發布的熱門文章《How I’d Become a Quant If I Had to Start Over Tomorrow》,由翻書Flip編譯和重新整理。
(前情提要:不靠佣金、不曬單,一名交易員只憑分析週期的常勝策略 )
(背景補充:頂級加密女交易員萬字生存筆記:別被「速成致富」毀掉 )
本文目錄
Toggle
- Part I:機率論,不確定性的語言
- Part II:統計學——學會聆聽數據
- Part III:線性代數——驅動一切的機器
- Part IV:微積分與最佳化——變化的語言
- Part V:隨機微積分——真正的 Quant 門檻
- Polymarket
- LMSR 如何為信念定價
- 量化交易職涯版圖:四種原型
- 工具箱與書單
- 三件作者希望自己早點知道的事
編譯聲明:本文不構成投資建議,市場有風險,請做好自己的研究。
先說幾個數字:2025 年,頂尖機構的應屆 Quant 年薪總包在 30 萬至 50 萬美元之間。金融業 AI/ML 招聘年增 88%。這條路,有沒有地圖?
這篇文章,是作者希望自己起步時有人能遞給他的東西。學習路線按照「你應該學的順序」排好了,每個概念都建立在前一個之上,就像電玩遊戲一樣,你沒辦法跳關。但如果你真的認真做,不是去 YouTube 上看什麼無聊的金融入門影片(那只是浪費時間),而是真的解題、動手做——大概 18 個月,你就能從什麼都不懂,變成真的懂一些東西。
把所有你以為知道的交易知識先放旁邊。大多數人以為量化交易是在選股、對特斯拉有看法、預測財報。其實不是。Quant 交易是數學。你做的是統計關係、定價低效率,以及那些「市場是被會犯系統性錯誤的人在跑的複雜系統」這個事實所帶來的結構性優勢。
Part I:機率論,不確定性的語言
量化金融的每件事,最後都可以簡化成一個問題:勝率多少?勝率站在我這邊嗎?
這就是機率。如果你對機率沒有深刻的理解,這篇文章後面的東西對你來說都沒有意義。
條件機率:Quant 的思考方式
一般人用絕對值思考:這件事是真的還是假的。Quant 用條件思考:根據我現在知道的,這件事有多大的機率?
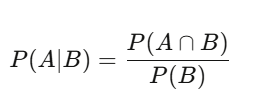
P(A|B) = P(A∩B) / P(B)——給定 B 發生,A 的機率等於兩者同時發生的機率除以 B 的機率。聽起來簡單,但影響很深遠。一支股票有 60% 的天數是上漲的——這是基礎機率。但在成交量高於平均的日子,上漲機率是 75%。這個條件機率才是有意義的資訊;原本那個 60% 反而充滿雜訊。
貝氏定理:即時更新你的判斷
後驗 = (在假說成立的情況下,看到這筆資料的機率)× 先驗 ÷ (在任何假說下,看到這筆資料的總機率)。在實作中,你用蒙地卡羅取樣來計算。邏輯是一樣的:貝氏是你在面對新資訊時即時調整判斷的方式。模型說一支股票應該值 50 美元,財報出來,營收比預期高 3%——貝氏後驗向上移動。更新最快、更新最準的人,贏得報酬。
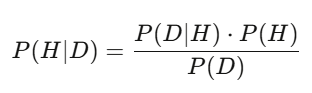
期望值與變異數:你最好的兩個朋友
期望值是你的信念強度;變異數是你的風險。如果你的策略有正期望值,而且你能撐過變異數帶來的震盪,你很可能會賺錢。
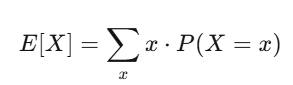
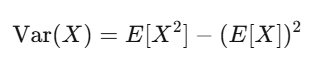
Level 1 作業(每天 2 小時,3-4 週)
-
讀:Blitzstein & Hwang,《Introduction to Probability》(哈佛免費 PDF),把第 1-6 章每道題目都做一遍
-
寫程式:模擬 10,000 次拋硬幣,用視覺化驗證大數法則
-
寫程式:自己實作一個貝氏更新器,輸入先驗和似然,輸出後驗
import numpy as np import matplotlib.pyplot as plt
大數法則:執行平均收斂到真實機率
np.random.seed(42) flips = np.random.choice([0, 1], size=10000, p=[0.5, 0.5]) running_avg = np.cumsum(flips) / np.arange(1, 10001)
plt.figure(figsize=(10, 4)) plt.plot(running_avg, linewidth=0.7) plt.axhline(y=0.5, color=‘r’, linestyle=‘–’, label=‘真實機率’) plt.xlabel(‘拋擲次數’) plt.ylabel(‘執行平均’) plt.title(‘大數法則實際演示’) plt.legend() plt.savefig(‘lln.png’, dpi=150) print(f"10,000 次後: {running_avg[-1]:.4f}(真實: 0.5000)")
Part II:統計學——學會聆聽數據
學會說機率這個語言之後,你要學的是從數據中聽出什麼。統計學教給你的第一課是:大多數看起來有意義的發現,其實只是雜訊。

假說檢定:你的濾雜訊偵測器
你建了一個模型,回測年化報酬率 15%。這是真的嗎?設立虛無假說 H₀:「這個策略的期望報酬是零」,計算檢定統計量,算出 p 值。但注意:如果你測試 1,000 個隨機策略,純靠運氣,就有 50 個 p 值會低於 0.05。這是多重比較問題。解法是 Bonferroni 修正(顯著水準除以測試次數),或 Benjamini-Hochberg 控制偽發現率。每個初學者都大幅高估自己找到了什麼有意義的東西。你前 10 個策略全部都是雜訊。現在就接受這件事,幫自己省很多錢。
回歸分析:拆解報酬
線性回歸 y=Xβ+ε 是金融業的主力工具。你把策略報酬對已知的風險因子做回歸,截距 α 就是你的超額報酬——那個無法被已知因子解釋的部分。
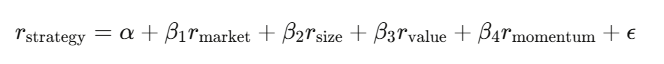
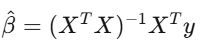
如果在控制各因子後 α 為零,你所謂的「優勢」只是偽裝過的市場曝險。要用 Newey-West 標準誤,因為金融數據有自相關和異質變異,用普通最小平方法的標準誤,就像開著裂掉的擋風玻璃在高速公路上行駛。
最大概似估計(MLE)
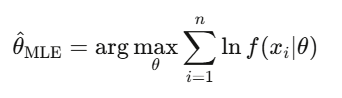
這是金融業校正每個模型的方法,不管是配適 GARCH 波動率模型、估計跳躍擴散參數,還是把選擇權定價校正到市場報價。當有人說「calibrating」一個模型,幾乎都是在說 MLE。
Level 2 作業(4-5 週)
- 讀:Wasserman,《All of Statistics》,第 1-13 章
- 下載真實股票報酬(yfinance),測試常態性(一定會失敗),用 MLE 配適 t 分布,比較結果
- 用 statsmodels 對股票組合跑 Fama-French 三因子回歸
- 實作排列測試:把日期打亂 10,000 次,把打亂後的績效和真實績效比較
Part III:線性代數——驅動一切的機器
線性代數聽起來很無聊,但它是驅動一切的機器:投資組合建構、主成分分析、神經網路、共變異數估計、因子模型。不會矩陣,就做不了 Quant。

矩陣思維
共變異數矩陣 Σ 捕捉了每一個資產相對於其他每個資產的移動方式。對於 500 支股票,Σ 是 500×500 的矩陣,有 125,250 個獨特的值。組合變異數可以簡化成一個表達式:w’Σw,這個二次型是 Markowitz 投資組合理論、風險管理、所有東西的核心。
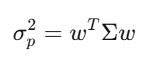
特徵值:真正重要的東西
看 500 支股票的宇宙,前 5 個特徵向量解釋了 70% 的總變異。其他的都是雜訊。第一次用特徵值分解,世界就變了:這是降維,也是因子投資的基礎。
Level 3 作業(4-6 週)
-
看:Gilbert Strang 的 MIT 18.06 線性代數課程,全部,不能跳過
-
讀:Strang,《Introduction to Linear Algebra》,把題目做完
-
對 S&P 500 報酬做 PCA,畫特徵值頻譜,找出前三個主成分
-
從頭實作 Markowitz 均值變異數最佳化
import numpy as np import cvxpy as cp
np.random.seed(42) n_assets = 10 mu = np.random.uniform(0.04, 0.15, n_assets) A = np.random.randn(n_assets, n_assets) * 0.1 cov = A @ A.T + np.eye(n_assets) * 0.01
w = cp.Variable(n_assets) objective = cp.Minimize(cp.quad_form(w, cov)) constraints = [ mu @ w >= 0.08, # 最低報酬要求 cp.sum(w) == 1, # 完全投入 w >= -0.1, # 最多 10% 放空 w <= 0.3 # 最多 30% 做多 ]
prob = cp.Problem(objective, constraints) prob.solve()
ret = mu @ w.value vol = np.sqrt(w.value @ cov @ w.value) sharpe = (ret - 0.03) / vol
print(f"組合報酬: {ret:.4f}“) print(f"組合波動: {vol:.4f}”) print(f"夏普比率: {sharpe:.4f}")
Part IV:微積分與最佳化——變化的語言
微積分是描述變化的語言。在金融裡,什麼都在變:價格、波動率、相關性,整個機率分布每秒都在移動。微積分描述並利用這些變化。導數出現在每個神經網路的反向傳播和每個選擇權希臘字母計算中。
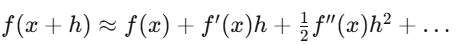
泰勒展開式是 Delta 避險的一階近似,Gamma 避險加入二階修正。Itô 微積分和普通微積分不同,正是因為隨機過程的二階泰勒項不會消失。
Level 4 作業(4-5 週)
- 讀:Boyd & Vandenberghe,《Convex Optimization》(史丹佛免費 PDF),第 1-5 章
- 從頭實作梯度下降,最小化 Rosenbrock 函數
- 用 cvxpy 解一個含交易成本約束的投資組合最佳化問題
Part V:隨機微積分——真正的 Quant 門檻
學隨機微積分之前,你只是個喜歡金融的數據科學家。學完之後,你才算是 Quant。這是你學會在連續時間裡建模隨機性、從第一原理推導 Black-Scholes 方程式,以及理解為什麼上兆美元的衍生品市場是這樣運作的地方。

布朗運動:將隨機性形式化
布朗運動(維納過程)W_t 是連續時間的隨機漫步。最關鍵的洞察——後面一切都依賴於此——是 dW_t 的「大小」是 √dt,意思是 (dW_t)² = dt。聽起來像技術細節,但這是量化金融裡最重要的一個事實。
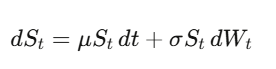
Itô 引理
在普通微積分裡,你做泰勒展開,(dx)² 小到可以省略。但當 x 是隨機過程,(dW_t)² = dt 是一階項,你省略不了。Itô 引理:df = (∂f/∂t + μ∂f/∂x + ½σ²∂²f/∂x²)dt + σ∂f/∂x dW_t。把這個應用到選擇權價格,你就得到了 Black-Scholes。
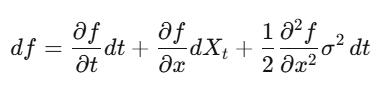
從頭推導 Black-Scholes
Step 1:設 V(S,t) 是選擇權價格,對其用 Itô 引理。
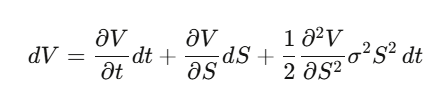
Step 2:建立 Delta 避險投資組合 Π = V − (∂V/∂S)·S,計算 dΠ——dW_t 項完美消掉,這個組合在局部是無風險的。
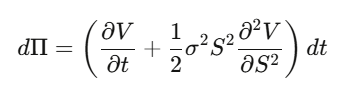
Step 3:無風險投資組合必須以無風險利率增值。
Step 4:代入整理,得到 Black-Scholes 偏微分方程式。
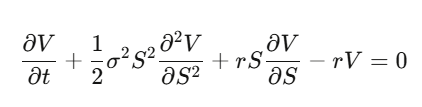
注意發生了什麼事:漂移率 μ 消失了。選擇權的價格跟股票的預期報酬無關,跟風險偏好也無關。你可以把每個人都當成風險中性來替選擇權定價。第一次真正理解這件事,真的會讓人腦袋打結。
對於一個履約價為 K、到期日為 T 的歐式買權,解這個偏微分方程(PDE)可以得到:
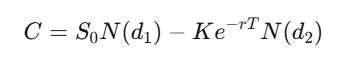
where d_1=
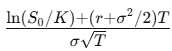
d_2=
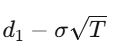
希臘字母
-
Delta Δ:每 1 美元股價移動,選擇權移動多少,也就是你的避險比率
-
Gamma Γ:Delta 變化的速度,你的凸性曝險
-
Theta Θ:時間價值損耗,長部位通常是負值
-
Vega V:對波動率的敏感度,大多數衍生品的錢在這裡賺
-
Rho ρ:對利率的敏感度
import numpy as np from scipy.stats import norm
def black_scholes(S, K, T, r, sigma, option_type=‘call’): d1 = (np.log(S/K) + (r + sigma**2/2)T) / (sigmanp.sqrt(T)) d2 = d1 - sigmanp.sqrt(T) if option_type == ‘call’: return Snorm.cdf(d1) - Knp.exp(-rT)norm.cdf(d2) else: return Knp.exp(-r*T)norm.cdf(-d2) - Snorm.cdf(-d1)
def monte_carlo_option(S0, K, T, r, sigma, n_sims=500_000): Z = np.random.standard_normal(n_sims) ST = S0 * np.exp((r - sigma**2/2)T + sigmanp.sqrt(T)Z) payoffs = np.maximum(ST - K, 0) price = np.exp(-rT) * np.mean(payoffs) stderr = np.exp(-r*T) * np.std(payoffs) / np.sqrt(n_sims) return price, stderr
S, K, T, r, sigma = 100, 105, 1.0, 0.05, 0.2 bs = black_scholes(S, K, T, r, sigma) mc, err = monte_carlo_option(S, K, T, r, sigma) print(f"Black-Scholes: ${bs:.4f}“) print(f"Monte Carlo: ${mc:.4f} ± {err:.4f}”)
Level 5 作業(6-8 週,最難的一關)
- 讀:Shreve,《Stochastic Calculus for Finance II》,金標準
- 替代選項:Arguin,《A First Course in Stochastic Calculus》,新一點,更容易入門
- 自己推導:對 f(S) = ln(S) 用 Itô 引理,推出那個 -σ²/2
- 自己推導:完整的 Black-Scholes 方程式,從 Delta 避險論證開始
- 寫程式:從頭實作 Black-Scholes,和蒙地卡羅比較,驗證收斂
Polymarket
這是目前世界上最有趣的市場,而其背後的數學把本文中的所有主題連結在一起:
機率(probability)、資訊理論(information theory)、凸優化(convex optimization)、整數規劃(integer programming)。
LMSR 如何為信念定價
對數市場評分規則(Logarithmic Market Scoring Rule,LMSR)
由 Robin Hanson 發明,用於驅動自動化的預測市場。
對於 n 個結果(outcomes),其成本函數為:
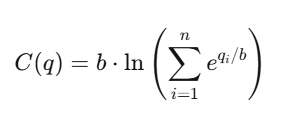
其中:
-
qiqi 表示 結果 i 已經發行的未平倉份額(outstanding shares)
-
bb 是 流動性參數(liquidity parameter)
結果 i 的價格為:
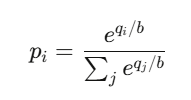
這其實就是 softmax 函數 ——
也就是 所有神經網路分類器(neural network classifiers)背後使用的函數。
其性質包括:
-
所有價格 加總永遠等於 1
-
所有價格 永遠落在 (0,1) 之間
-
市場 始終存在價格,等同於提供無限流動性
而 做市商(market maker)的最大損失
被限制在:b×ln(n)b×ln(n)
量化交易職涯版圖:四種原型
Quant Researcher(QR):在 PB 級數據裡找規律,建預測模型,設計策略,需要博士級數學/統計/機器學習,或是大學階段就特別突出的人。在 Jane Street 這類機構,QR 手邊有幾萬張 GPU。
Quant Developer/Engineer(QD):負責建造,交易平台、執行引擎、即時數據管道,讓研究員的模型真的能跑起來交易。需要生產級別的 C++/Rust/Python 和低延遲系統。
Quant Trader(QT):決策者,管理資本、控制風險、做即時判斷。薪資變異最大,頂尖年份可以到八位數。
Risk Quant:守門人,模型驗證、VaR、壓力測試、法規遵循,職涯路徑比較穩定,但天花板較低。新興的 AI/ML Quant 角色(用深度學習產生信號)是成長最快的方向,2025 年招聘年增 88%。
薪資行情如下(美國頂尖機構,Jane Street、Citadel、HRT):
- 應屆畢業生:$30 萬至 $50 萬+總包
- 中階(3-7 年):$55 萬至 $95 萬
- 資深(8 年+):$100 萬至 $300 萬+
- 明星交易員/PM:$300 萬至 $3000 萬+
中型機構(Two Sigma、DE Shaw)應屆畢業生約 $25 萬至 $35 萬總包。Jane Street 的員工平均薪酬在 2025 上半年達到每年 140 萬美元,這是平均值。
面試流程:履歷篩選 → 線上測試(心算用 Zetamac,目標 50 分以上,邏輯題)→ 電話面試(機率問題、賭博遊戲)→ Superday(3-5 輪連續面試,模擬交易、程式碼、白板推導)。Jane Street 故意出難到自己解不完的題,測的是你怎麼利用提示和跟人協作。他們近期實習生班超過三分之二讀資工,三分之一讀數學,金融知識通常不要求。
面試準備首推 Xinfeng Zhou 的《Green Book》(量化金融面試實戰指南,200 道以上真實題目),搭配 QuantGuide.io(量化版 LeetCode)和 Brainstellar 練習。
工具箱與書單
Python 技術棧:數據處理用 pandas/polars(Polars 在大型數據集上快 10-50 倍),數值計算用 numpy/scipy,表格型機器學習用 xgboost/lightgbm,深度學習用 pytorch,最佳化用 cvxpy,衍生品用 QuantLib,統計用 statsmodels,回測用 NautilusTrader 或 vectorbt。
免費數據來源:yfinance、Finnhub(每分鐘 60 次請求)、Alpha Vantage。中階用 Polygon.io(每月 $199,延遲低於 20ms)。企業級是 Bloomberg Terminal(每年約 $32,000)。
書單(按順序)
- 數學基礎:Blitzstein & Hwang《機率論》→ Strang《線性代數》→ Wasserman《All of Statistics》→ Boyd & Vandenberghe《凸最佳化》→ Shreve《隨機微積分 I & II》
- 量化金融:Hull《選擇權、期貨與其他衍生品》→ Natenberg《選擇權波動率與定價》→ López de Prado《金融機器學習進階》→ Ernest Chan《量化交易》→ Zuckerman《解開市場謎題的人》
- 面試:Zhou《Green Book》→ Crack《Heard on the Street》→ Joshi《Quant 面試題》
- 競賽:Jane Street Kaggle(10 萬美元獎金)、WorldQuant BRAIN(超過 10 萬用戶,付錢買 alpha 信號)、Citadel Datathon(快速通道到正職)
三件作者希望自己早點知道的事
**估計誤差才是真正的敵人。**Full Kelly 下注、無約束 Markowitz、特徵數量太多的機器學習模型——失敗的原因都一樣:過度擬合參數估計中的雜訊。數學在真實參數下完美運作。你從來沒有真實參數。理論和實踐之間的差距,永遠都是估計誤差,最好的 Quant 是那些真正尊重這件事的人。
**工具已經民主化,但判斷力沒有。**任何人都能取得 QuantLib、Polygon.io 和 PyTorch。技術是必要條件,但不是充分條件。優勢存在於獨特的數據、獨特的模型,或是獨特的執行能力,不在於更好的 pip install。
**數學是護城河。**AI 可以寫程式碼、提議策略。但能夠推導出為什麼 Itô 引理有那個多出來的項、能夠證明在風險中性測度下折現價格是鞅、能夠知道在組合套利問題中凸鬆弛是緊的還是鬆的——這種數學流暢度,才是區分「建立優勢的 Quant」和「借用別人優勢的 Quant」的東西。借來的優勢有到期日。

免責聲明:本頁面資訊可能來自第三方,不代表 Gate 的觀點或意見。頁面顯示的內容僅供參考,不構成任何財務、投資或法律建議。Gate 對資訊的準確性、完整性不作保證,對因使用本資訊而產生的任何損失不承擔責任。虛擬資產投資屬高風險行為,價格波動劇烈,您可能損失全部投資本金。請充分了解相關風險,並根據自身財務狀況和風險承受能力謹慎決策。具體內容詳見聲明。
留言
0/400
暫無留言