CryptOpus
$ETHUSDT 在突破支撐趨勢線後出現拋售,正如預測的那樣。我們已經獲得了3%的利潤。如果它突破了當前的支撐,下一個目標是下方的支撐。希望大家都從我們的更新中獲利,所以#Pin our channel for more! #加密貨幣
查看原文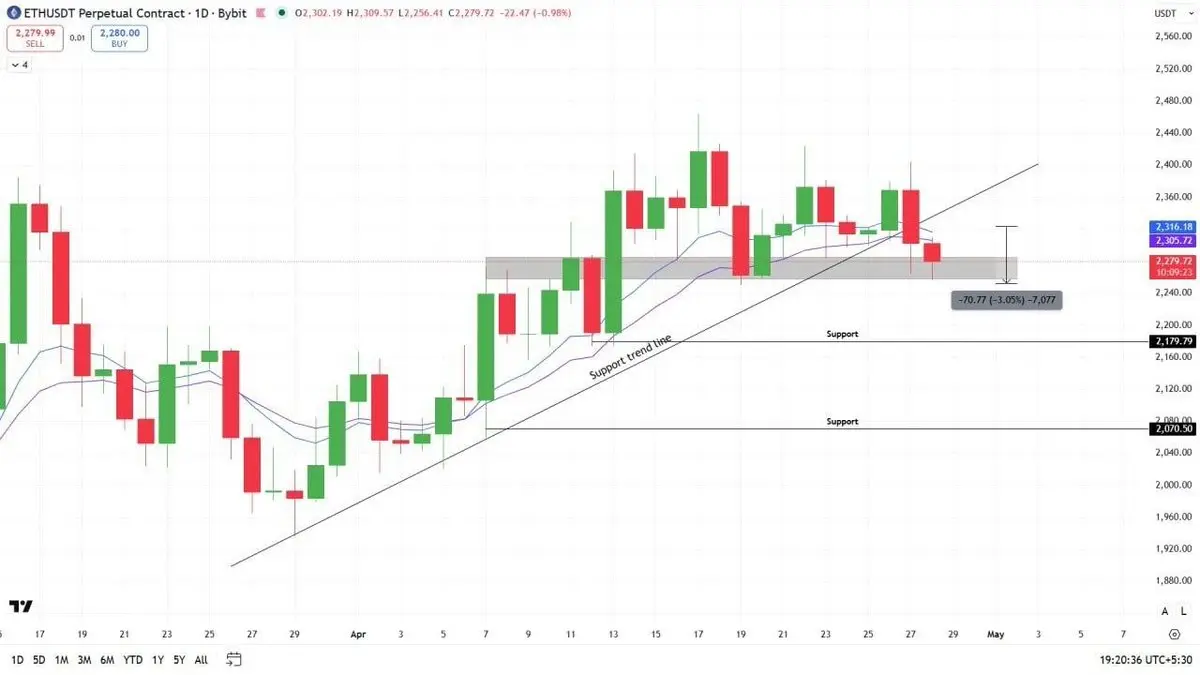
- 打賞
- 按讚
- 留言
- 轉發
- 分享
前天在深圳吃饭不幸丢失百达斐丽5811一块,现捡到的朋友愿意给3Wu,请求扩散一下有现货的也有奖赏
查看原文
- 打賞
- 按讚
- 留言
- 轉發
- 分享
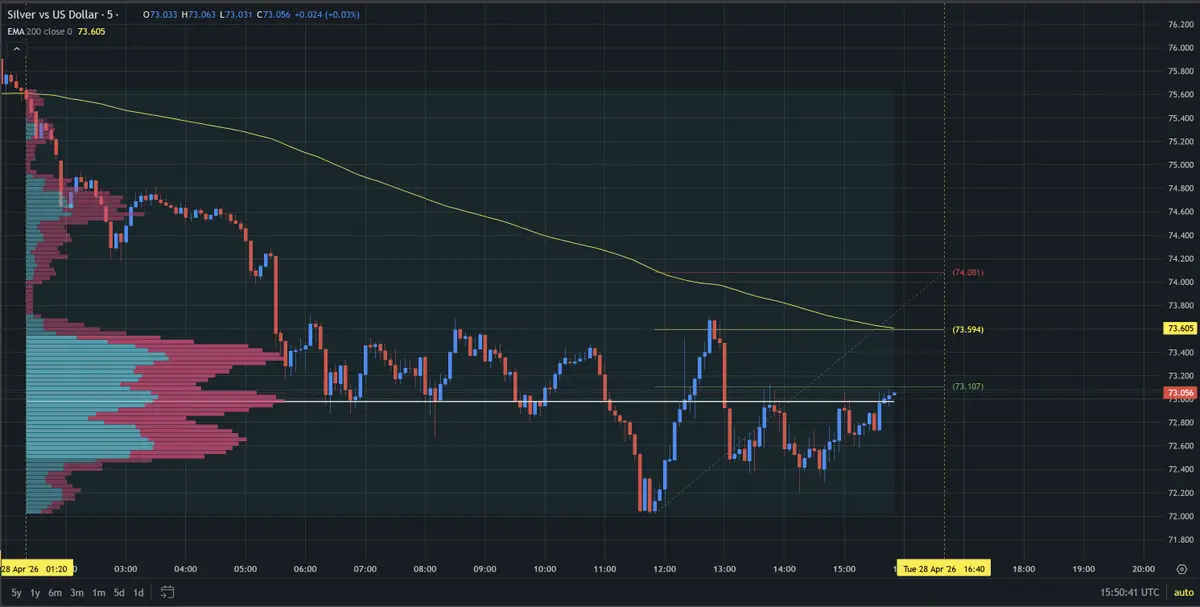
#XAG/USD
SC02 M5 - 未平倉賣出訂單。進入點位位於 LVN 內 + 不受任何弱區影響,當前阻力區約寬 0.65%。下跌趨勢已持續 14 小時 30 分鐘,最大記錄價格下跌幅度為 4.73%。如果價格突破此阻力區,很有可能趨勢將反轉向上。
SC02 M5 - 未平倉賣出訂單。進入點位位於 LVN 內 + 不受任何弱區影響,當前阻力區約寬 0.65%。下跌趨勢已持續 14 小時 30 分鐘,最大記錄價格下跌幅度為 4.73%。如果價格突破此阻力區,很有可能趨勢將反轉向上。
查看原文
- 打賞
- 按讚
- 留言
- 轉發
- 分享
#SolanaReleasesQuantumRoadmap
區塊鏈行業正以快速的步伐發展,Solana 再次憑藉其備受期待的量子路線圖(Quantum Roadmap)站在創新的前沿。這一前瞻性策略概述了 Solana 如何為其生態系統未來抵禦新興技術挑戰——尤其是量子計算對區塊鏈安全的潛在影響。
在其核心,量子路線圖專注於增強加密韌性。隨著量子計算的不斷進步,傳統的加密方法在大多數區塊鏈中使用,最終可能變得脆弱。Solana 的積極主動方法凸顯其對長期安全的承諾,通過探索抗量子加密算法來實現。這些先進技術旨在即使在後量子時代,也能保障用戶資產、智能合約和網絡完整性。
路線圖的另一個關鍵方面是擴展性。Solana 已以其高吞吐量和低交易成本而聞名,但新計劃旨在進一步提升網絡效率。通過整合尖端技術和優化共識機制,Solana 打算保持其競爭優勢,同時支持對去中心化應用程序(dApps)、DeFi 平台和 NFT 生態系統日益增長的需求。
該路線圖還強調開發者賦能。Solana 計劃推出新工具、SDK 和教育資源,幫助開發者構建量子安全的應用程序。這一舉措預計將吸引更多創新進入生態系統,並確保在技術演進中,基於 Solana 的項目保持韌性。
互操作性也是另一個重點。Solana 旨在改善跨鏈通信,實現不同區塊鏈網絡之間的無縫交互。在多條鏈共存與合作的未來,這一點尤為重要,並且安全標
區塊鏈行業正以快速的步伐發展,Solana 再次憑藉其備受期待的量子路線圖(Quantum Roadmap)站在創新的前沿。這一前瞻性策略概述了 Solana 如何為其生態系統未來抵禦新興技術挑戰——尤其是量子計算對區塊鏈安全的潛在影響。
在其核心,量子路線圖專注於增強加密韌性。隨著量子計算的不斷進步,傳統的加密方法在大多數區塊鏈中使用,最終可能變得脆弱。Solana 的積極主動方法凸顯其對長期安全的承諾,通過探索抗量子加密算法來實現。這些先進技術旨在即使在後量子時代,也能保障用戶資產、智能合約和網絡完整性。
路線圖的另一個關鍵方面是擴展性。Solana 已以其高吞吐量和低交易成本而聞名,但新計劃旨在進一步提升網絡效率。通過整合尖端技術和優化共識機制,Solana 打算保持其競爭優勢,同時支持對去中心化應用程序(dApps)、DeFi 平台和 NFT 生態系統日益增長的需求。
該路線圖還強調開發者賦能。Solana 計劃推出新工具、SDK 和教育資源,幫助開發者構建量子安全的應用程序。這一舉措預計將吸引更多創新進入生態系統,並確保在技術演進中,基於 Solana 的項目保持韌性。
互操作性也是另一個重點。Solana 旨在改善跨鏈通信,實現不同區塊鏈網絡之間的無縫交互。在多條鏈共存與合作的未來,這一點尤為重要,並且安全標
SOL-0.84%
- 打賞
- 按讚
- 留言
- 轉發
- 分享
- 打賞
- 按讚
- 留言
- 轉發
- 分享
#StraitOfHormuz #IranUSNegotiations
#GateSquareDaily
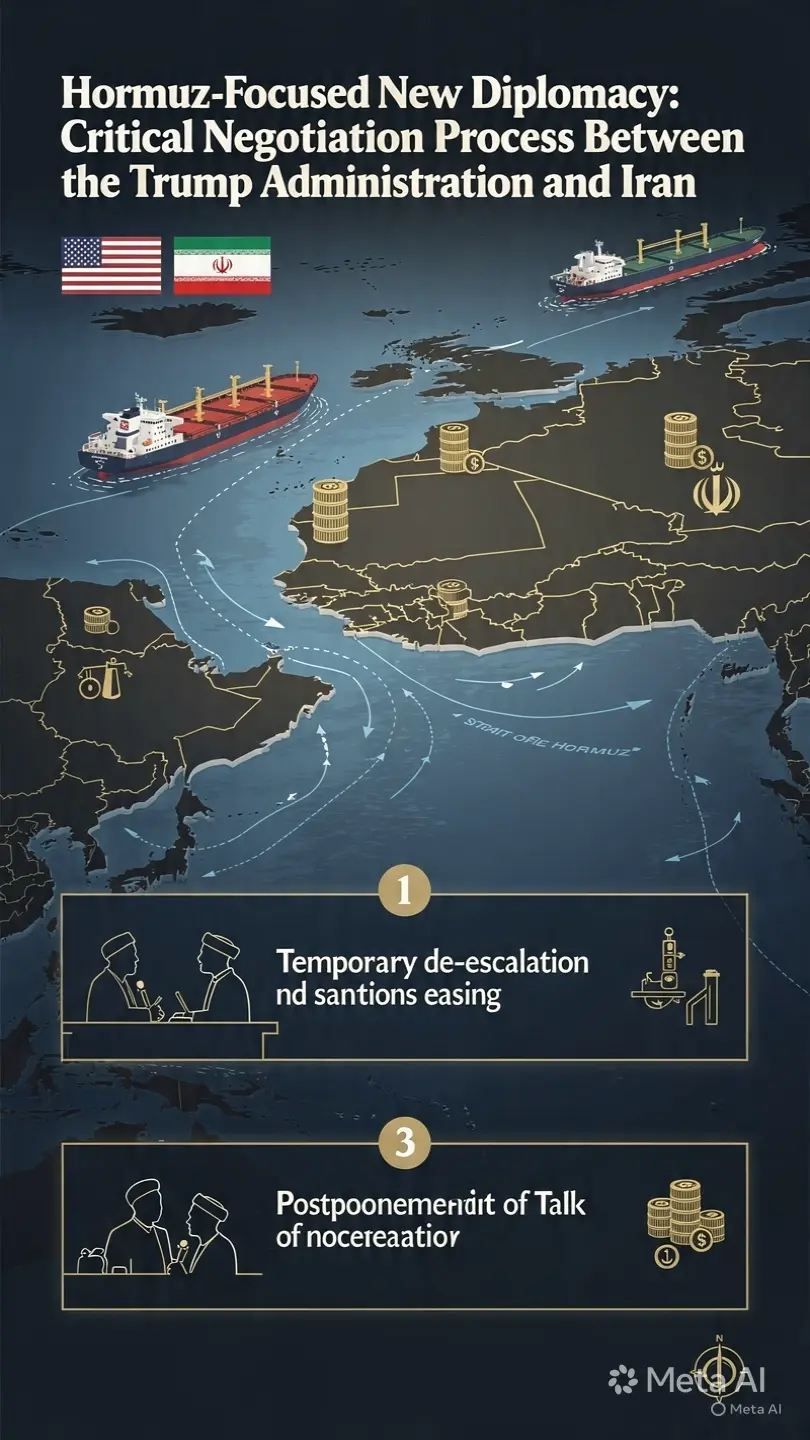
霍爾木茲焦點新外交:特朗普政府與伊朗之間的關鍵談判過程
截至2026年,中東地緣政治再次見證一場高強度的外交危機,正在重塑全球格局。一場由唐納德·特朗普的國家安全團隊在華盛頓召開的關鍵會議,評估伊朗提交的一項新談判提案。這一發展正作為多層次外交進程的一部分,特別圍繞霍爾木茲海峽的地位。
伊朗的三階段談判計劃
根據目前的報導,伊朗的提案並非單一的停火倡議,而是一個結構化的三階段戰略框架:
重新開放霍爾木茲海峽並恢復海上交通
暫時緩解地區衝突並部分放寬制裁
推遲核談判至後期階段
這一做法表明,德黑蘭的優先事項是創造立即的“經濟喘息空間”並恢復其能源出口能力。通過該海峽的全球約20%的石油供應流量,位於此計劃的核心位置。
華盛頓的回應與戰略保留
美國對該提案持謹慎態度。根據提交給特朗普國家安全團隊的評估,華盛頓的主要關切是推遲核文件的處理。
美國的立場圍繞三個核心要求:
直接且立即參與伊朗的核計劃
明確承諾關於濃縮鈾儲存量
建立一個可驗證且永久的霍爾木茲海峽自由通行制度
因此,美國政府將伊朗的提案視為一種“部分且階段性的讓步模式”,並認為這可能帶來戰略風險。
霍爾木茲海峽:全球能源安全的核心
霍爾木茲海峽不僅僅是一條區域水道,更是全球能源系統中最關鍵的動脈之一。近期的緊張局勢再次
查看原文#GateSquareDaily
霍爾木茲焦點新外交:特朗普政府與伊朗之間的關鍵談判過程
截至2026年,中東地緣政治再次見證一場高強度的外交危機,正在重塑全球格局。一場由唐納德·特朗普的國家安全團隊在華盛頓召開的關鍵會議,評估伊朗提交的一項新談判提案。這一發展正作為多層次外交進程的一部分,特別圍繞霍爾木茲海峽的地位。
伊朗的三階段談判計劃
根據目前的報導,伊朗的提案並非單一的停火倡議,而是一個結構化的三階段戰略框架:
重新開放霍爾木茲海峽並恢復海上交通
暫時緩解地區衝突並部分放寬制裁
推遲核談判至後期階段
這一做法表明,德黑蘭的優先事項是創造立即的“經濟喘息空間”並恢復其能源出口能力。通過該海峽的全球約20%的石油供應流量,位於此計劃的核心位置。
華盛頓的回應與戰略保留
美國對該提案持謹慎態度。根據提交給特朗普國家安全團隊的評估,華盛頓的主要關切是推遲核文件的處理。
美國的立場圍繞三個核心要求:
直接且立即參與伊朗的核計劃
明確承諾關於濃縮鈾儲存量
建立一個可驗證且永久的霍爾木茲海峽自由通行制度
因此,美國政府將伊朗的提案視為一種“部分且階段性的讓步模式”,並認為這可能帶來戰略風險。
霍爾木茲海峽:全球能源安全的核心
霍爾木茲海峽不僅僅是一條區域水道,更是全球能源系統中最關鍵的動脈之一。近期的緊張局勢再次
- 打賞
- 6
- 5
- 轉發
- 分享
MrFlower_XingChen:
直達月球 🌕查看更多
第十三周年ETF特別活動全面展開
簽到,邀請好友賺取獎勵,累計交易翻倍
🎁 解鎖最高13倍獎勵倍數,最高可獲1,911 USDT
💰 共享額外50,000 USDT獎池,單人最高贏取1,300 USDT
🚀 獎勵已到位,你解鎖了多少倍數?
👉 現在加入:https://www.gate.com/campaigns/4498
📢 更多詳情:https://www.gate.com/zh/announcements/article/50717
查看原文簽到,邀請好友賺取獎勵,累計交易翻倍
🎁 解鎖最高13倍獎勵倍數,最高可獲1,911 USDT
💰 共享額外50,000 USDT獎池,單人最高贏取1,300 USDT
🚀 獎勵已到位,你解鎖了多少倍數?
👉 現在加入:https://www.gate.com/campaigns/4498
📢 更多詳情:https://www.gate.com/zh/announcements/article/50717


- 打賞
- 2
- 留言
- 轉發
- 分享
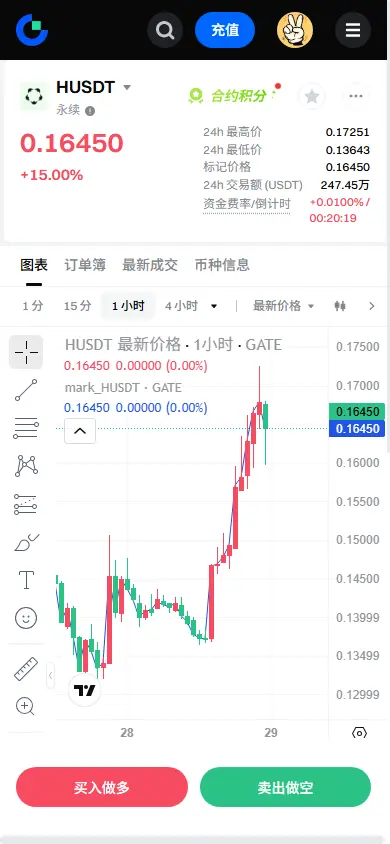
【$H 信號】短線回調接多,1H RSI超買待修復
RSI 1H 71.47,資金推動力減弱。布林帶1H上軌0.1690壓制,價格連續兩根1H收陰。買單比例1.46顯示下方接盤積極,但高位追多盈虧比極差。4H MACD金叉延續,趨勢仍向上。當前盈虧比僅0.14,等待回調至支撐區域更穩妥。
🎯方向:做多(回調掛單)
⚡入場/掛單:0.16374
🛑止損:0.13602
🚀目標1:0.16774
🚀目標2:0.17832
🛡️交易管理:
- 執行策略:到達目標1後減倉50%,並將止損上移至保本位。若價格跌回入場位,自動離場,保護本金。
深度邏輯:1H MACD柱狀開始萎縮,多頭動能衰減。但4H布林中軌0.1478及EMA20_1h 0.1524構成層層支撐。此處掛單既避免踏空又控制風險。
查看實時行情 👇 $H
---
關注我:獲取更多加密市場實時分析與洞察! $BTC $ETH $SOL
#WCTC交易王PK #加密市场小幅下跌 #Polymarket每日热点
查看原文RSI 1H 71.47,資金推動力減弱。布林帶1H上軌0.1690壓制,價格連續兩根1H收陰。買單比例1.46顯示下方接盤積極,但高位追多盈虧比極差。4H MACD金叉延續,趨勢仍向上。當前盈虧比僅0.14,等待回調至支撐區域更穩妥。
🎯方向:做多(回調掛單)
⚡入場/掛單:0.16374
🛑止損:0.13602
🚀目標1:0.16774
🚀目標2:0.17832
🛡️交易管理:
- 執行策略:到達目標1後減倉50%,並將止損上移至保本位。若價格跌回入場位,自動離場,保護本金。
深度邏輯:1H MACD柱狀開始萎縮,多頭動能衰減。但4H布林中軌0.1478及EMA20_1h 0.1524構成層層支撐。此處掛單既避免踏空又控制風險。
查看實時行情 👇 $H
---
關注我:獲取更多加密市場實時分析與洞察! $BTC $ETH $SOL
#WCTC交易王PK #加密市场小幅下跌 #Polymarket每日热点
- 打賞
- 按讚
- 留言
- 轉發
- 分享
$PI Pi的人工智能基礎設施:由100萬人工組成的分佈式團隊完成了5.26億項任務
人工智能發展迅速,但構建可靠系統的難點仍然在於人為因素。對於那些致力於改進模型、優化推理質量、或擴大數據標註與評估規模的公司來說,人類的參與依然是不可或缺的。
構建出色的模型並非僅僅依賴於更強大的計算能力:人工智能需要人類的參與來優化輸出結果、確定質量標準、驗證結果的準確性、消除歧義,從而確保這些系統真正能為人所用。
在那些條件明確、範圍有限的場景中,非人類輔助的優化方法和自動化訓練手段確實能發揮巨大作用,有助於提升優化效率。不過,它們也存在諸多局限性:它們往往只能優化某些替代指標,而無法真正反映人類的真實偏好;此外,這類方法容易受到獎勵機制被操縱的影響,同時也難以充分把握各種細微差別、各種行為的合理性、不断變化的規範以及人們在現實世界中的判斷標準。
正因如此,無論自動化技術如何發展,人類的參與對於人工智能的不断完善來說仍然是不可或缺的。
人工智能中人類輸入所帶來的實際挑戰
對人工干預的依賴給人工智能公司帶來了巨大的運營挑戰。
規模/程度
人工智能公司需要大量來自人類的輸入數據。在機器人技術和物理人工智能等新興領域,這一點尤為重要。因為未來的突破很可能取決於那些基於海量人類生成的數據而訓練出來的模型——這些數據涉及物理環境以及人類在現實世界中的各種互動行為。正如互聯網規模的數據是推動ChatGP
人工智能發展迅速,但構建可靠系統的難點仍然在於人為因素。對於那些致力於改進模型、優化推理質量、或擴大數據標註與評估規模的公司來說,人類的參與依然是不可或缺的。
構建出色的模型並非僅僅依賴於更強大的計算能力:人工智能需要人類的參與來優化輸出結果、確定質量標準、驗證結果的準確性、消除歧義,從而確保這些系統真正能為人所用。
在那些條件明確、範圍有限的場景中,非人類輔助的優化方法和自動化訓練手段確實能發揮巨大作用,有助於提升優化效率。不過,它們也存在諸多局限性:它們往往只能優化某些替代指標,而無法真正反映人類的真實偏好;此外,這類方法容易受到獎勵機制被操縱的影響,同時也難以充分把握各種細微差別、各種行為的合理性、不断變化的規範以及人們在現實世界中的判斷標準。
正因如此,無論自動化技術如何發展,人類的參與對於人工智能的不断完善來說仍然是不可或缺的。
人工智能中人類輸入所帶來的實際挑戰
對人工干預的依賴給人工智能公司帶來了巨大的運營挑戰。
規模/程度
人工智能公司需要大量來自人類的輸入數據。在機器人技術和物理人工智能等新興領域,這一點尤為重要。因為未來的突破很可能取決於那些基於海量人類生成的數據而訓練出來的模型——這些數據涉及物理環境以及人類在現實世界中的各種互動行為。正如互聯網規模的數據是推動ChatGP
PI6.16%

- 打賞
- 3
- 留言
- 轉發
- 分享
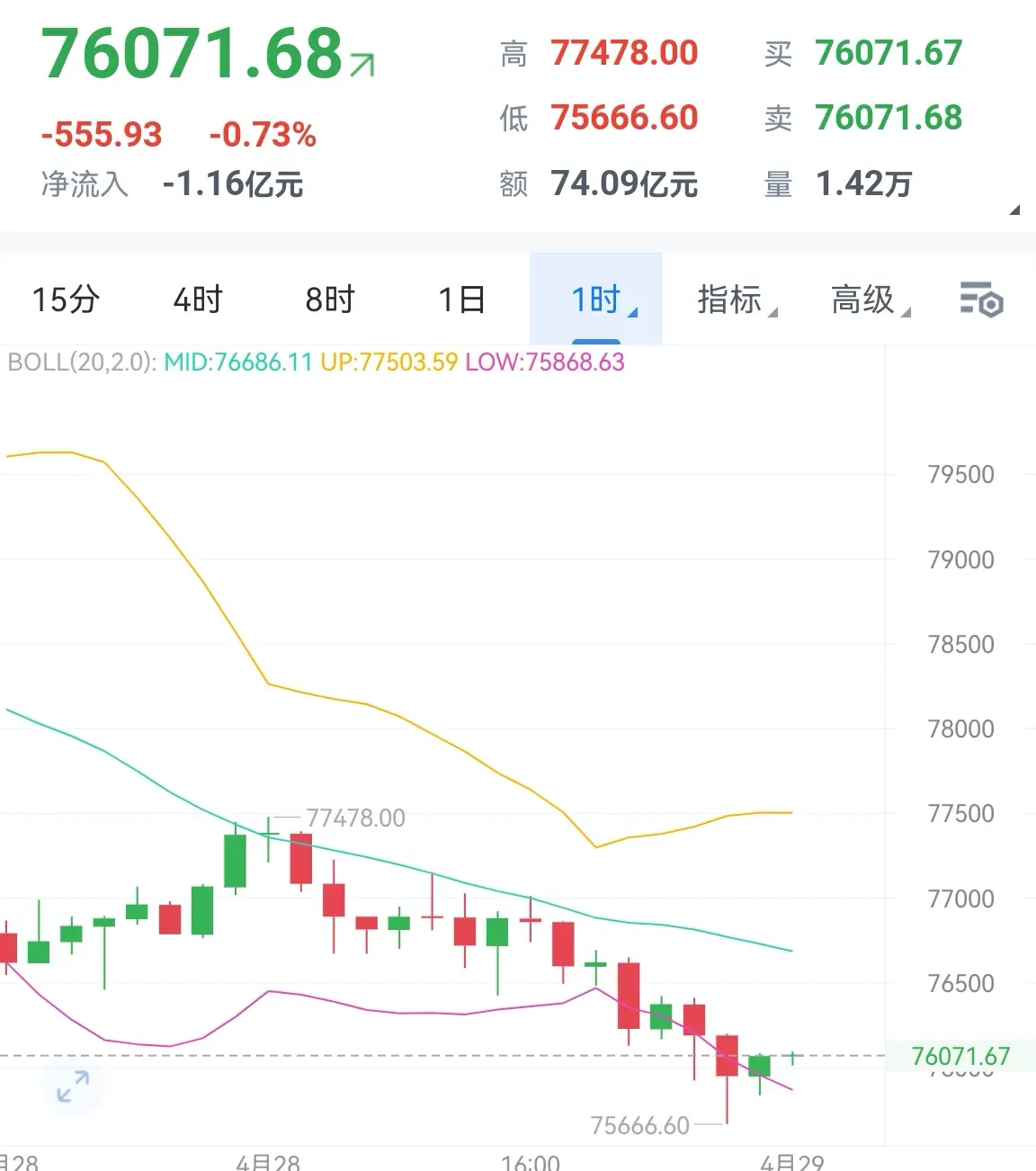
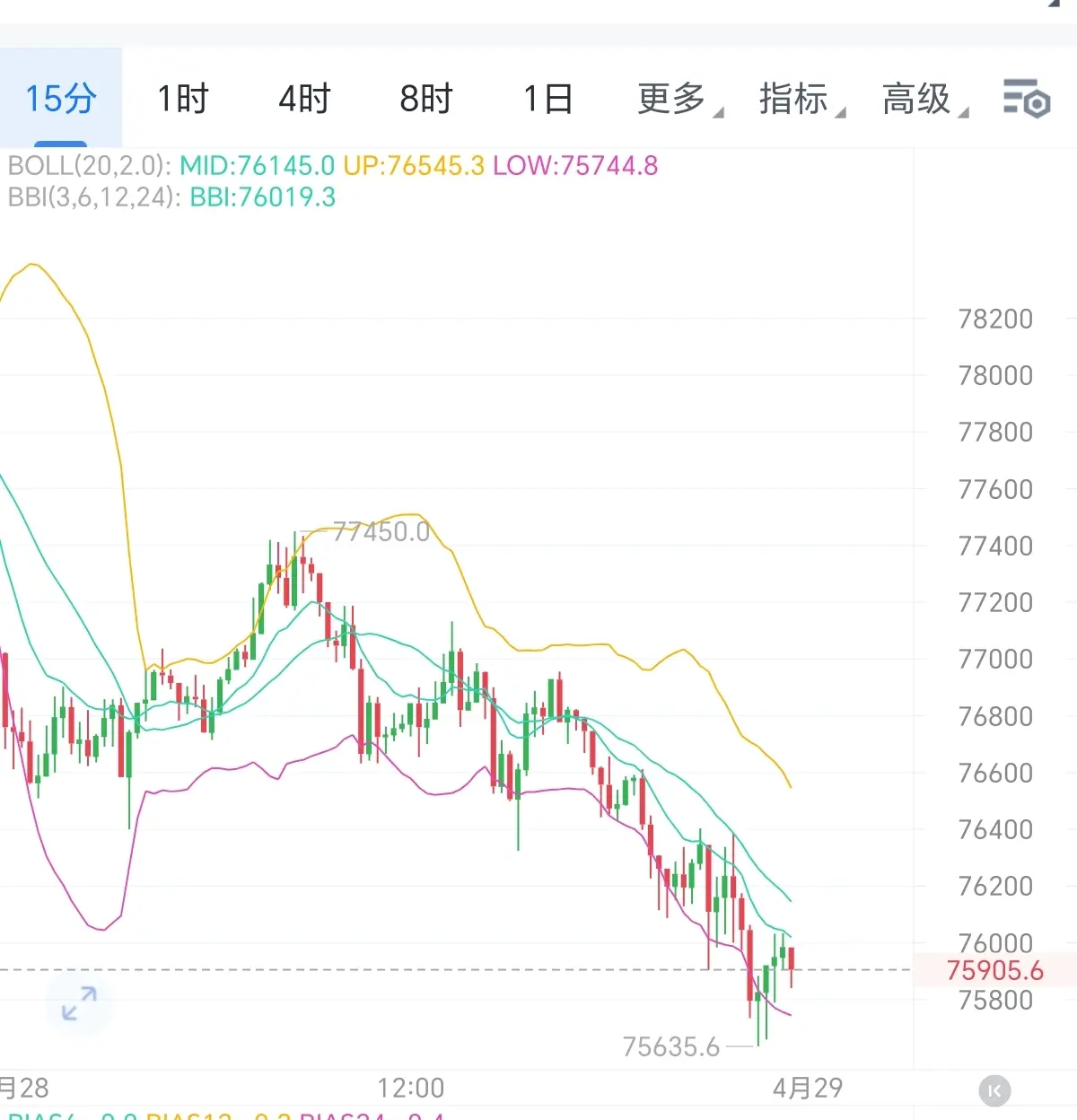
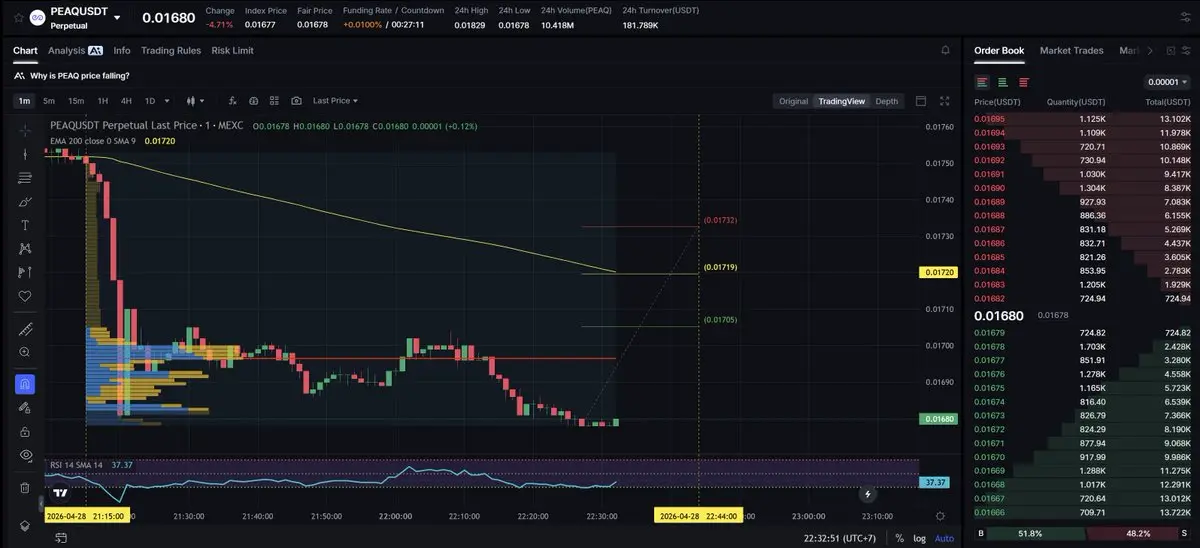
日內行情再次即將走完,昨日美股收盤後幣價走出觸底反彈,幣價向上反彈至7.74萬附近後再次延續了此前的回撤趨勢,行情持續慢跌至晚間美盤,向下試探低點7.56萬附近支撐後,幣價再度進入慢反彈修復階段,昨日晚間提示的凌晨看反彈修復思路精准拿捏,今日晚間提示的7.6萬下方進場的多單目前仍在持續持有當中,日內行情依舊還是弱勢反覆探底的節奏。
大餅四小時來看,幣價連續陰包陽持續向下快速跌落至下軌下方,當前幣價收出較長下影線,美股的持續回調也並沒有刺激到行情持續的回撤,那麼結合盤面反彈需求的持續擴大,後市我們看幣價的反彈修復。短期小時線來看,幣價中軌附近承壓後再次走出連陰快速回撤,當前幣價試探下軌下方支撐後收長下影線反彈修復,KDJ三線指標逐步匯拢逐步形成金叉,空頭短期持續縮量,短線思路我們持續看幣價的反彈修復,回撤短多參與即可。
大餅在75800附近,關注77000附近。二餅在2270附近多,關注2320附近。
#加密市场小幅下跌 #Polymarket每日热点 #WCTC交易王PK
大餅四小時來看,幣價連續陰包陽持續向下快速跌落至下軌下方,當前幣價收出較長下影線,美股的持續回調也並沒有刺激到行情持續的回撤,那麼結合盤面反彈需求的持續擴大,後市我們看幣價的反彈修復。短期小時線來看,幣價中軌附近承壓後再次走出連陰快速回撤,當前幣價試探下軌下方支撐後收長下影線反彈修復,KDJ三線指標逐步匯拢逐步形成金叉,空頭短期持續縮量,短線思路我們持續看幣價的反彈修復,回撤短多參與即可。
大餅在75800附近,關注77000附近。二餅在2270附近多,關注2320附近。
#加密市场小幅下跌 #Polymarket每日热点 #WCTC交易王PK
BTC-1.01%
- 打賞
- 按讚
- 留言
- 轉發
- 分享
晚安創作者 ✨
時間線越來越安靜……
但我們都知道有人仍在盯著參與度數據,就像在期末考試一樣 😭
@TheARCTERMINAL 是 AI 原生時代持續展開的地方
@useTria 讓鏈上生活感覺不再那麼壓力山大,而是更像流動
@quipnetwork 正在悄悄打造礦業的未來
@MindoAI 幫助每個 Web3 行動變得更聰明
輕輕退出。大聲回歸 🦊
查看原文時間線越來越安靜……
但我們都知道有人仍在盯著參與度數據,就像在期末考試一樣 😭
@TheARCTERMINAL 是 AI 原生時代持續展開的地方
@useTria 讓鏈上生活感覺不再那麼壓力山大,而是更像流動
@quipnetwork 正在悄悄打造礦業的未來
@MindoAI 幫助每個 Web3 行動變得更聰明
輕輕退出。大聲回歸 🦊

- 打賞
- 按讚
- 留言
- 轉發
- 分享
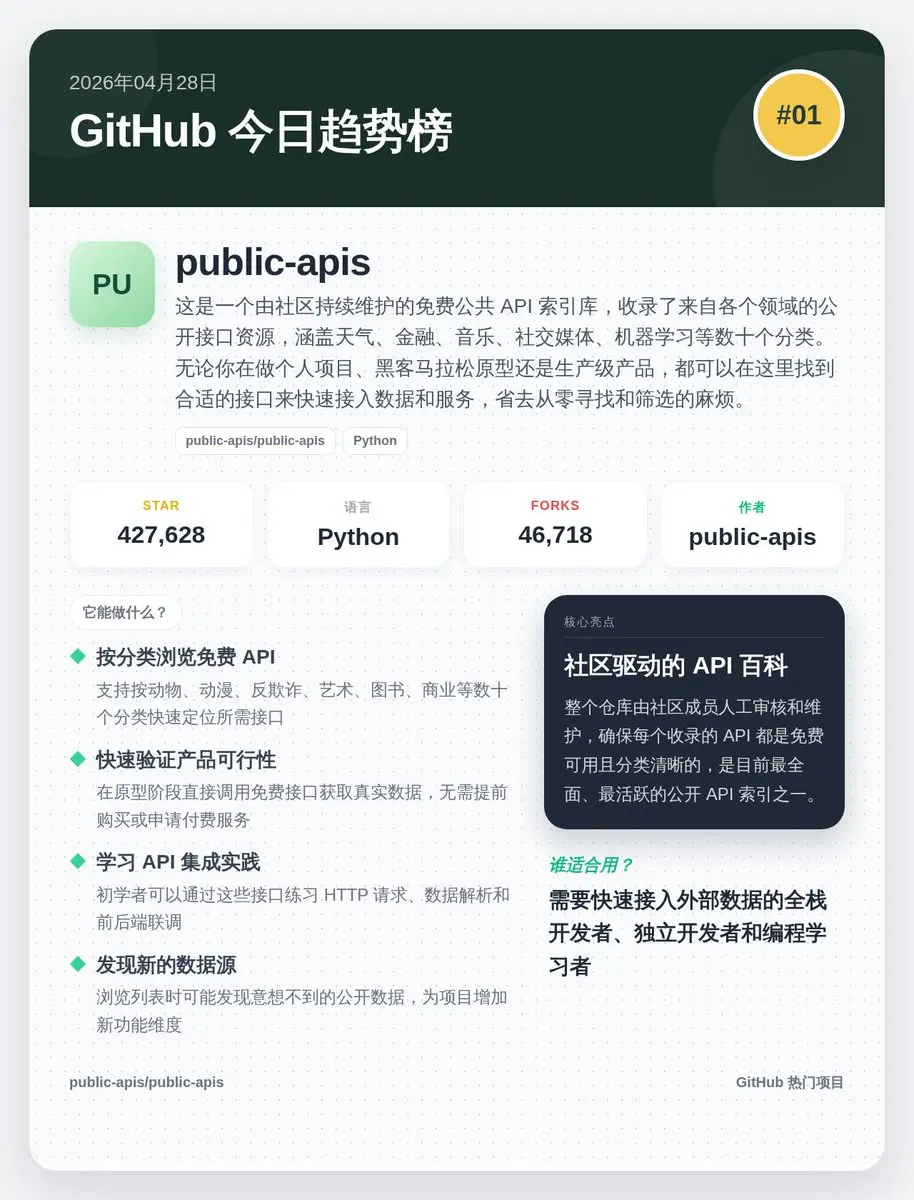
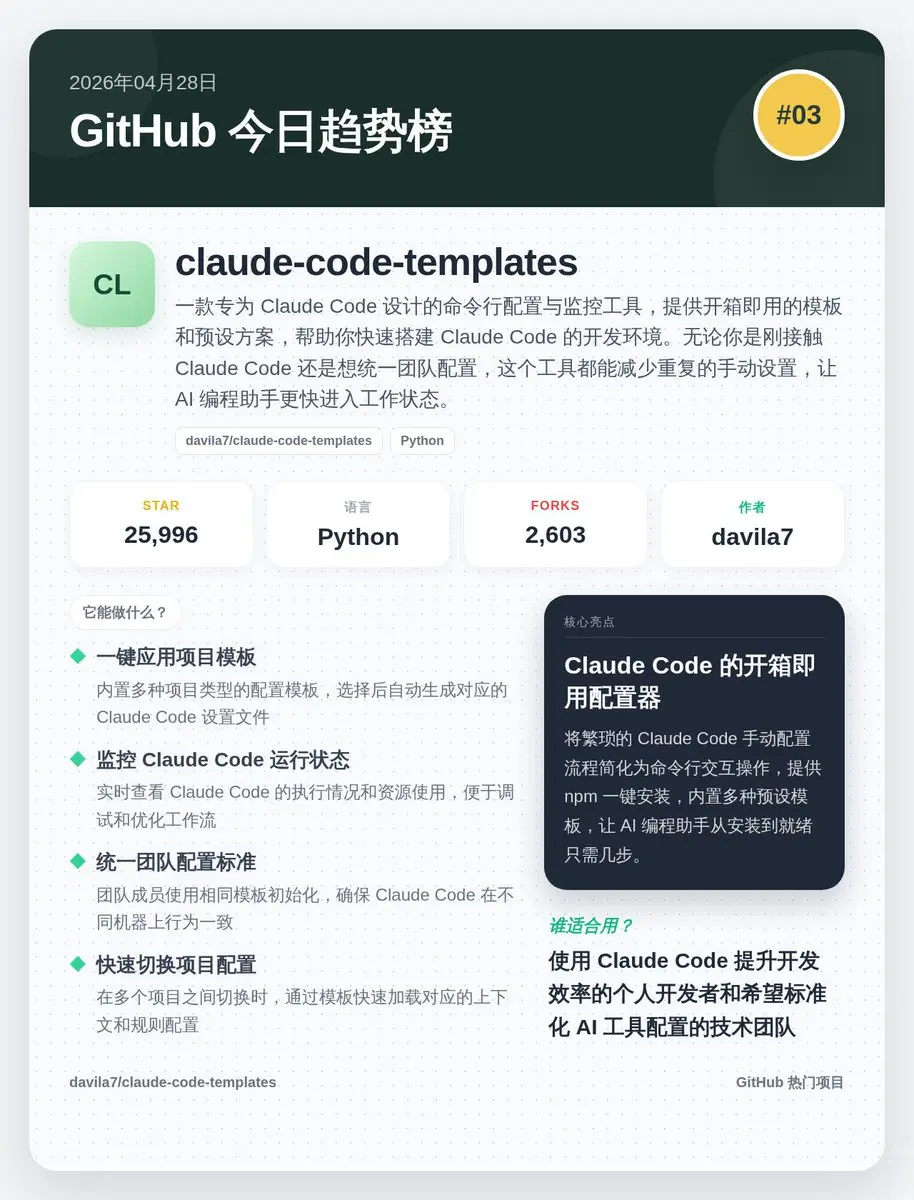
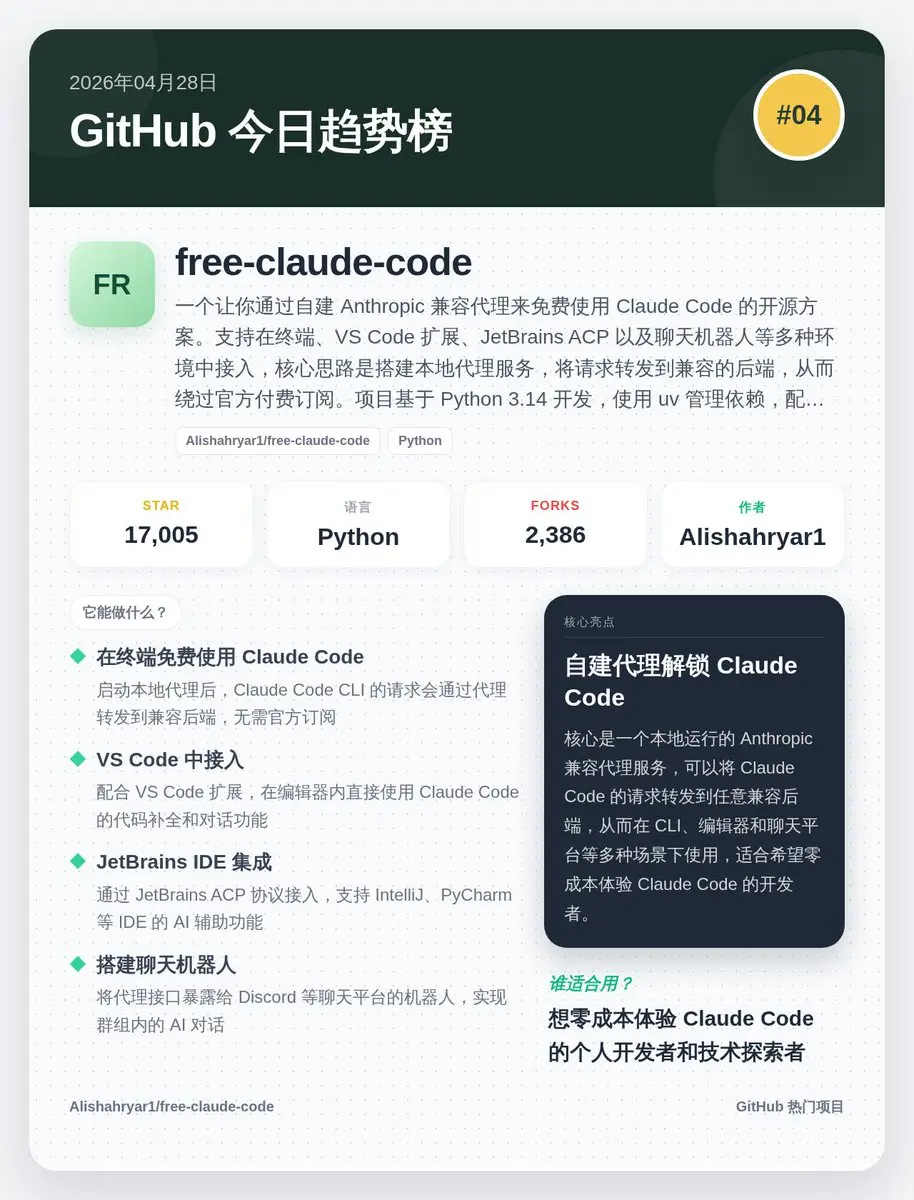
📅 2026年04月28日 GitHub 趨勢榜精選:
1️⃣ public-apis (#01): 42萬Star的API百科全書,找接口再也不用滿世界搜了!全棧開發者的效率神器。
2️⃣ free-programming-books (#02): 38萬Star的程式設計圖書館,上千本免費電子書隨便看,自學程式設計的起點。
3️⃣ claude-code-templates (#03): Claude Code的快捷配置器,一鍵搭建開發環境,AI程式設計效率翻倍。
4️⃣ free-claude-code (#04): 自建代理白嫖Claude Code,終端/VS Code都能用,零成本體驗AI程式設計。
哪一個是你今天的剛需?👇
查看原文1️⃣ public-apis (#01): 42萬Star的API百科全書,找接口再也不用滿世界搜了!全棧開發者的效率神器。
2️⃣ free-programming-books (#02): 38萬Star的程式設計圖書館,上千本免費電子書隨便看,自學程式設計的起點。
3️⃣ claude-code-templates (#03): Claude Code的快捷配置器,一鍵搭建開發環境,AI程式設計效率翻倍。
4️⃣ free-claude-code (#04): 自建代理白嫖Claude Code,終端/VS Code都能用,零成本體驗AI程式設計。
哪一個是你今天的剛需?👇

- 打賞
- 按讚
- 留言
- 轉發
- 分享

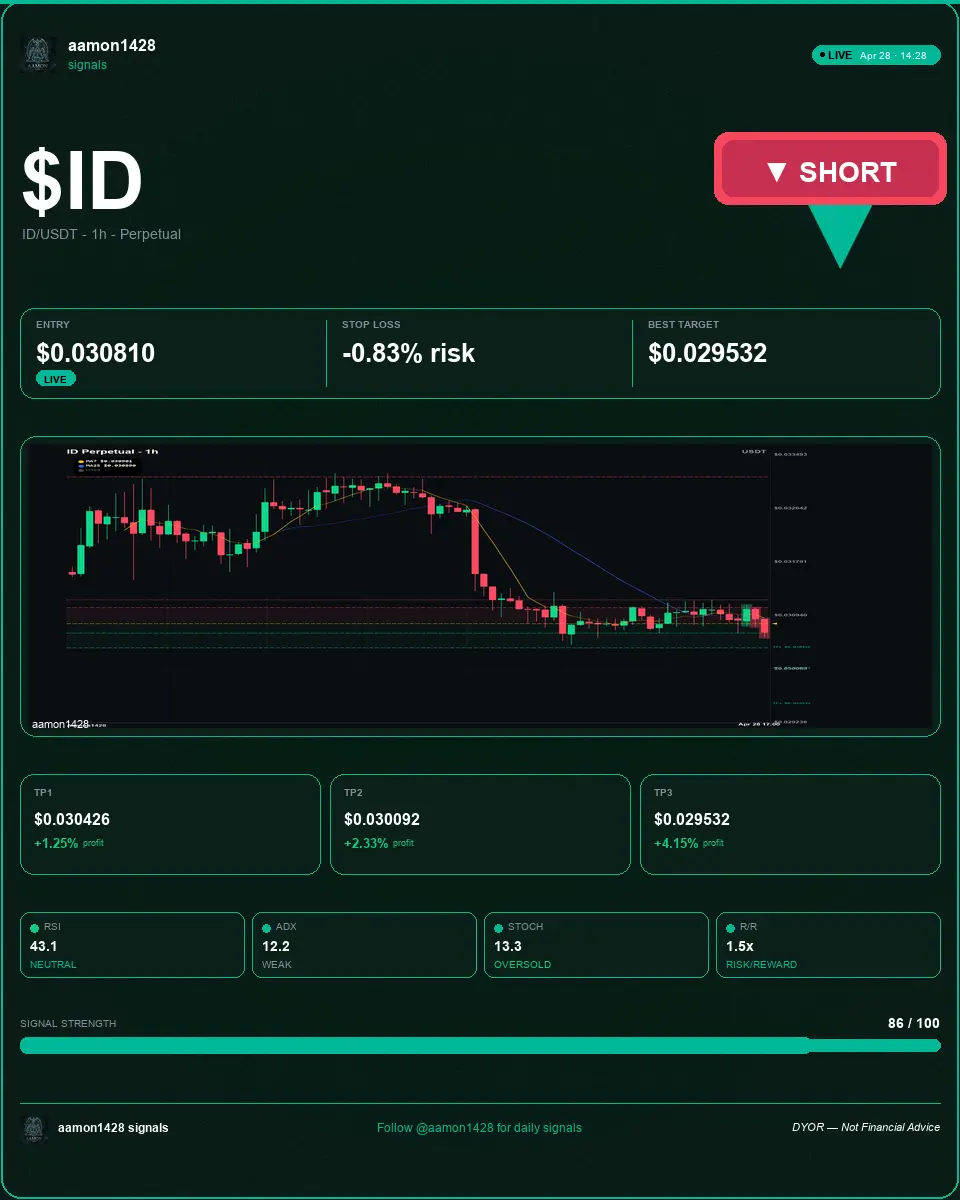
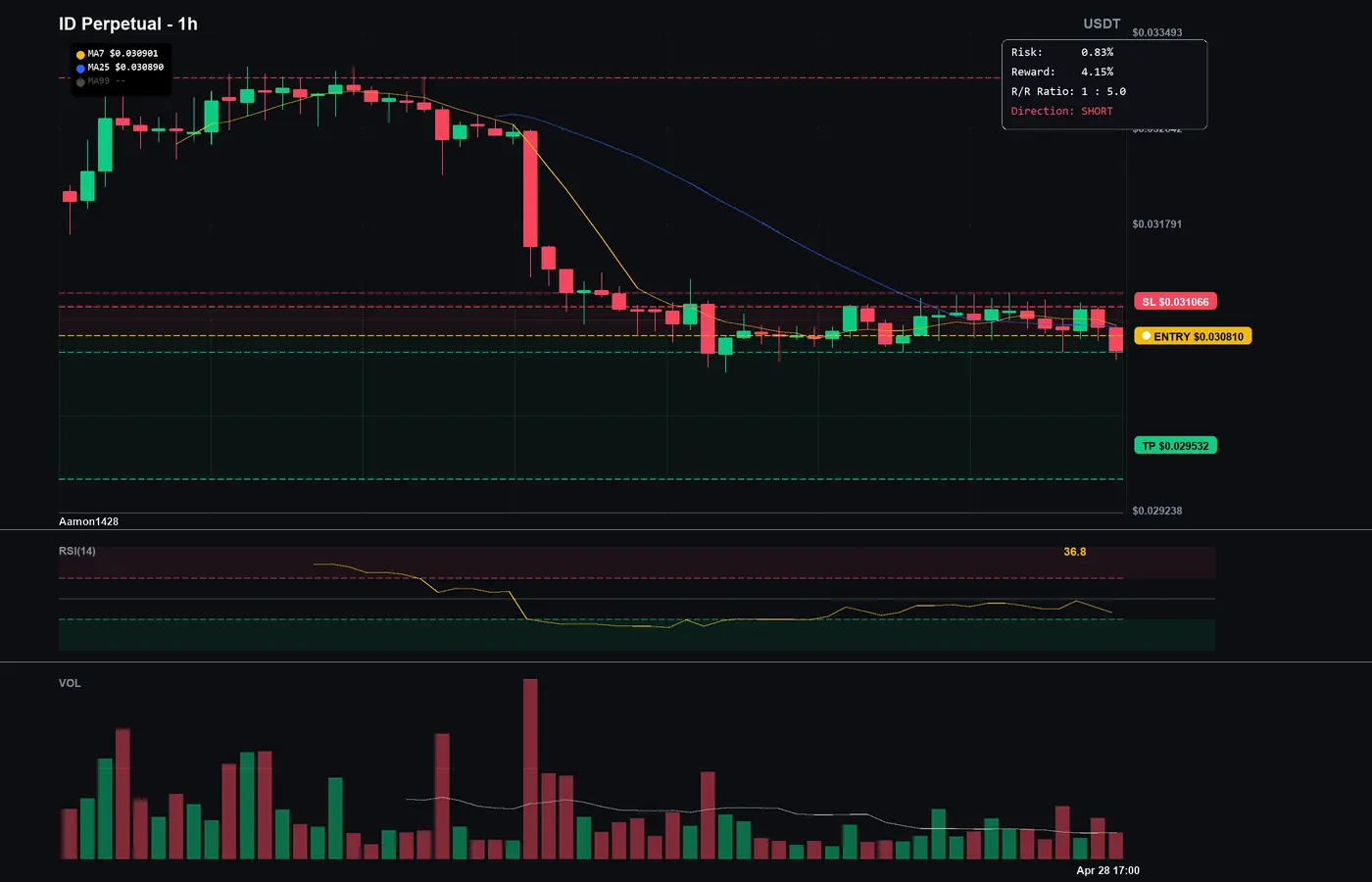
ID/USDT空頭結構檢查:無交叉,得分86/100。
ID/USDT空頭 (1小時)
進場 0.03081 | 止損 -0.83%
獲利點1 0.030426 (+-1.25%) | 獲利點2 0.030092 (+-2.33%) | 獲利點3 0.029532 (+-4.15%)
RSI 43.1 (中性) | ADX 12.2 (弱) | 隨機指標 50.0 (中性)
風險回報 1.50 | 強度 86/100
保持紀律並遵循水平。
#SolanaReleasesQuantumRoadmap #DailyPolymarketHotspot #ID
查看原文ID/USDT空頭 (1小時)
進場 0.03081 | 止損 -0.83%
獲利點1 0.030426 (+-1.25%) | 獲利點2 0.030092 (+-2.33%) | 獲利點3 0.029532 (+-4.15%)
RSI 43.1 (中性) | ADX 12.2 (弱) | 隨機指標 50.0 (中性)
風險回報 1.50 | 強度 86/100
保持紀律並遵循水平。
#SolanaReleasesQuantumRoadmap #DailyPolymarketHotspot #ID
- 打賞
- 按讚
- 留言
- 轉發
- 分享
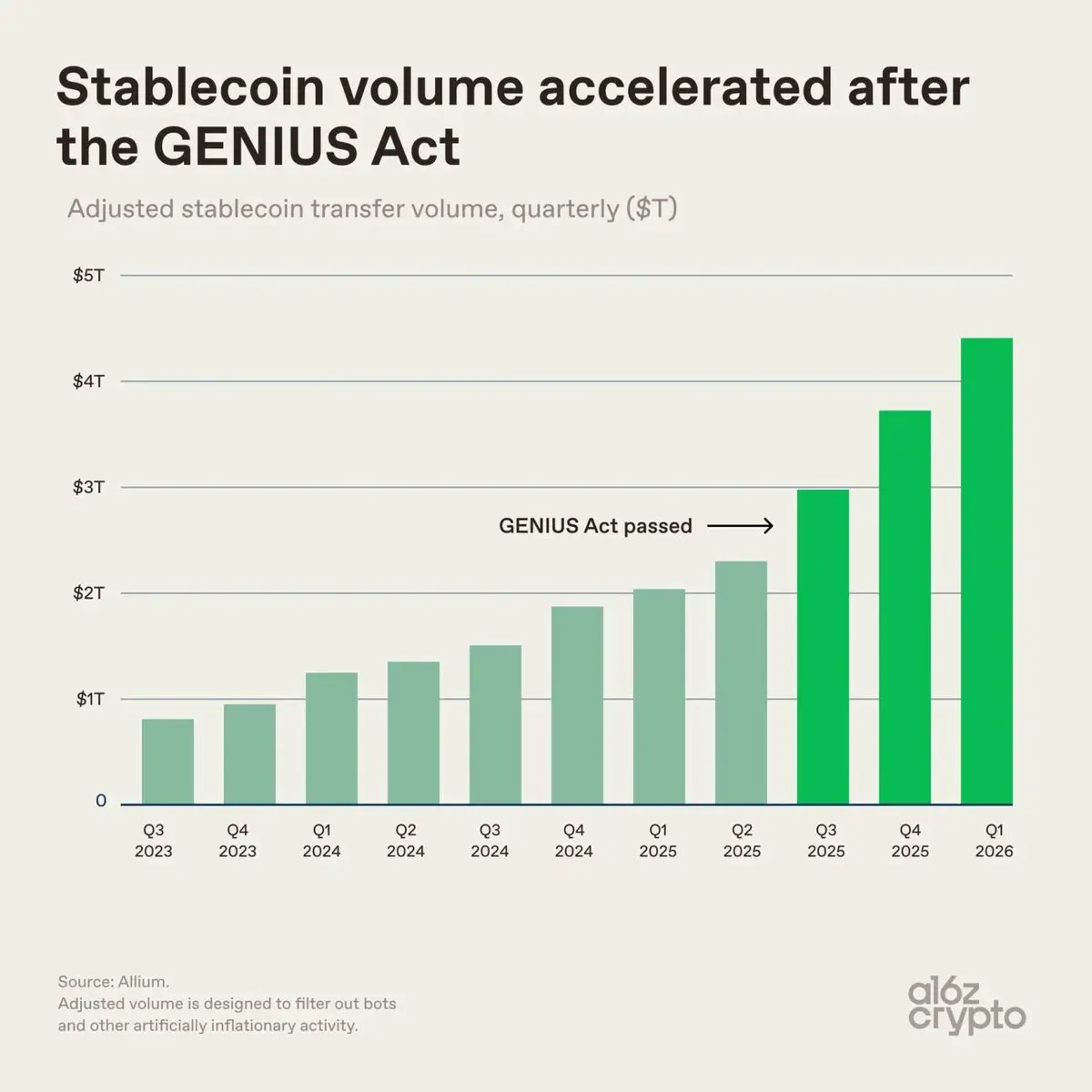
我記得穩定幣曾經只是個小眾的加密貨幣事物。
你用它們來更快地在交易所之間轉移資金,在波動期間停放美元,並在不離開加密貨幣的情況下保持流動性。
現在?
完全是另一個故事。
不是因為《天才法案》神奇地創造了需求。它實際上消除了機構面臨的最大阻礙之一,那就是不明確的規則。
看起來穩定幣已經從交易工具迅速轉變為金融軌道。
查看原文你用它們來更快地在交易所之間轉移資金,在波動期間停放美元,並在不離開加密貨幣的情況下保持流動性。
現在?
完全是另一個故事。
不是因為《天才法案》神奇地創造了需求。它實際上消除了機構面臨的最大阻礙之一,那就是不明確的規則。
看起來穩定幣已經從交易工具迅速轉變為金融軌道。
- 打賞
- 按讚
- 留言
- 轉發
- 分享
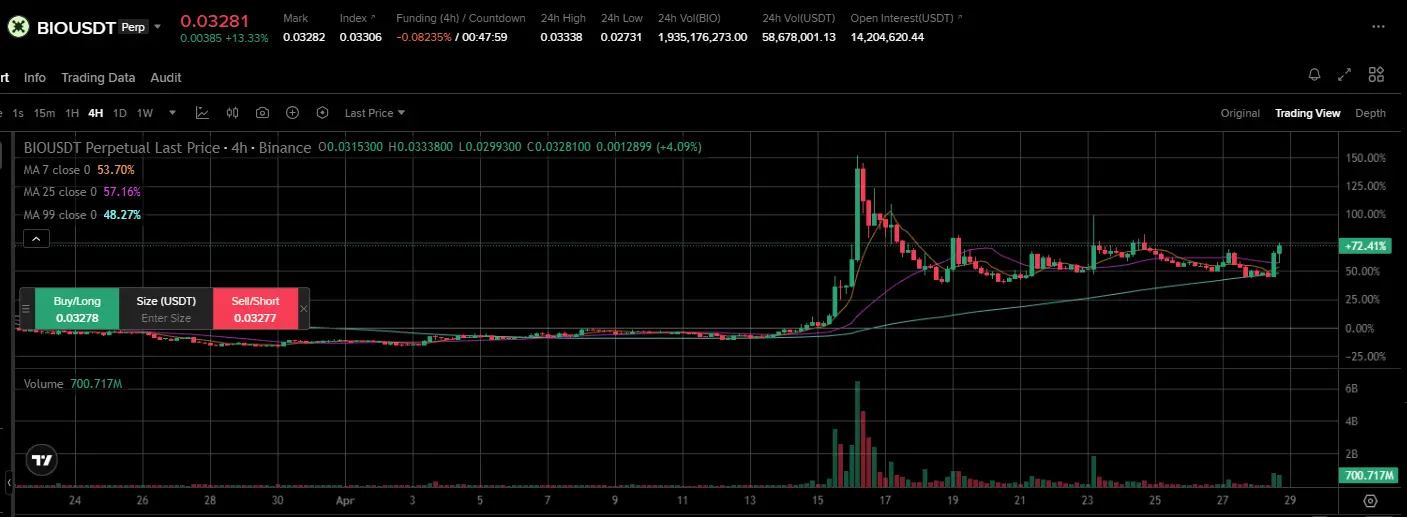
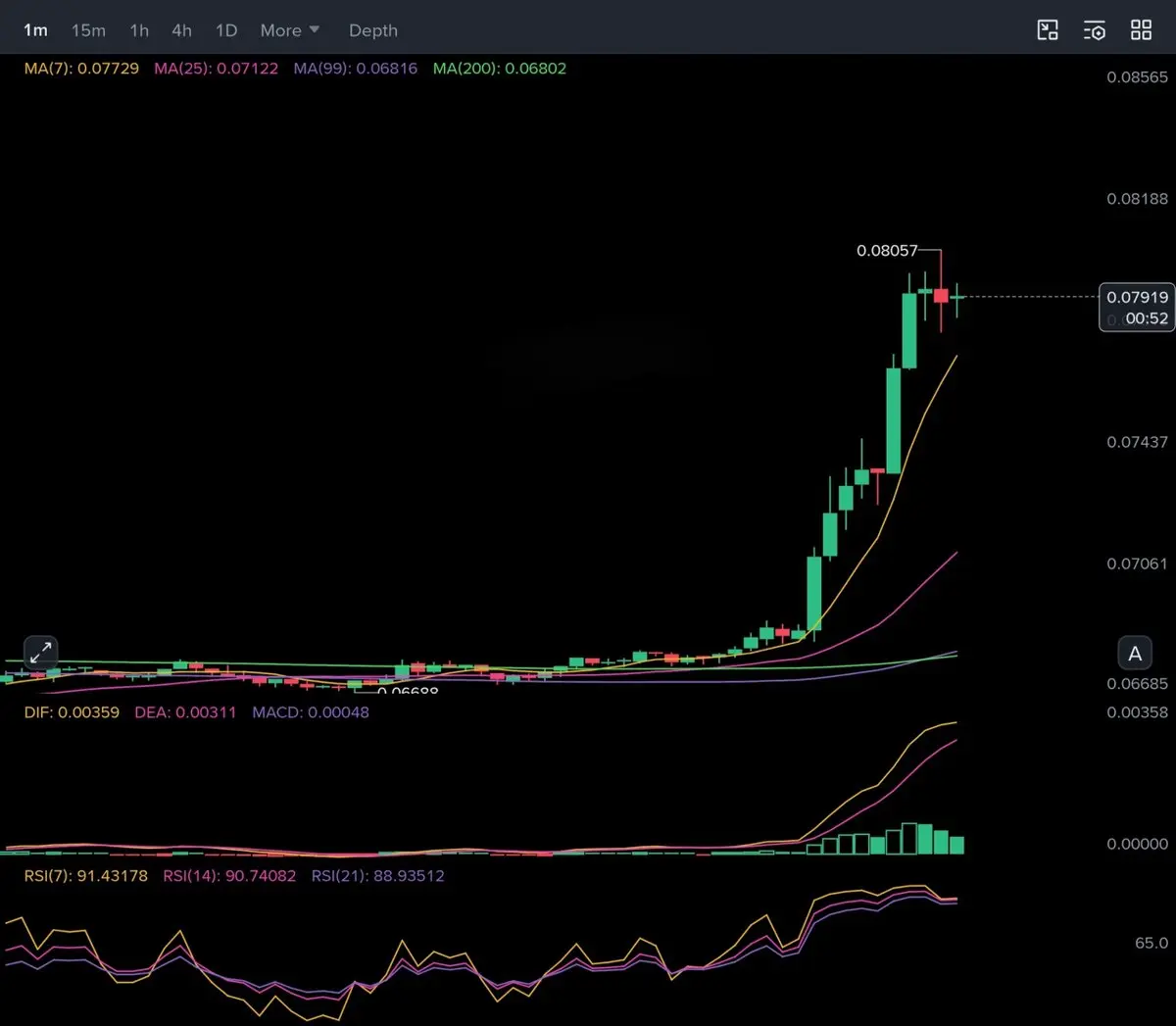
💰 $LYN 動量突破設定
🔼 多頭
✳️ 進場:0.0780 – 0.0750
🎯 目標:0.0810 – 0.08345 – 0.086290 – 0.08935 – 0.0970 – 0.1000
🀄️ 槓桿: 10倍
🔴 止損:0.0720
在收復所有主要移動平均線後,出現具有強烈垂直動能的爆炸性突破結構。MA7 明顯遠離 MA25 和 MA99,顯示激進的多頭加速。RSI 過熱嚴重,意味著波動性和回調預期 — 避免追高綠色蠟燭,專注於支撐區域附近的 DCA 進場。MACD 柱狀圖保持完全多頭,動能擴大,確認買方仍控制趨勢方向。只要價格保持在 MA25 之上並維持較高的低點,向心理突破目標繼續前進的可能性仍然很高。
🔼 多頭
✳️ 進場:0.0780 – 0.0750
🎯 目標:0.0810 – 0.08345 – 0.086290 – 0.08935 – 0.0970 – 0.1000
🀄️ 槓桿: 10倍
🔴 止損:0.0720
在收復所有主要移動平均線後,出現具有強烈垂直動能的爆炸性突破結構。MA7 明顯遠離 MA25 和 MA99,顯示激進的多頭加速。RSI 過熱嚴重,意味著波動性和回調預期 — 避免追高綠色蠟燭,專注於支撐區域附近的 DCA 進場。MACD 柱狀圖保持完全多頭,動能擴大,確認買方仍控制趨勢方向。只要價格保持在 MA25 之上並維持較高的低點,向心理突破目標繼續前進的可能性仍然很高。
查看原文
- 打賞
- 12
- 12
- 轉發
- 分享
GweiGossip:
垂直動量這個詞聽起來就刺激,實際交易還是等個回踩確認比較踏實,避免追高被套查看更多
查看原文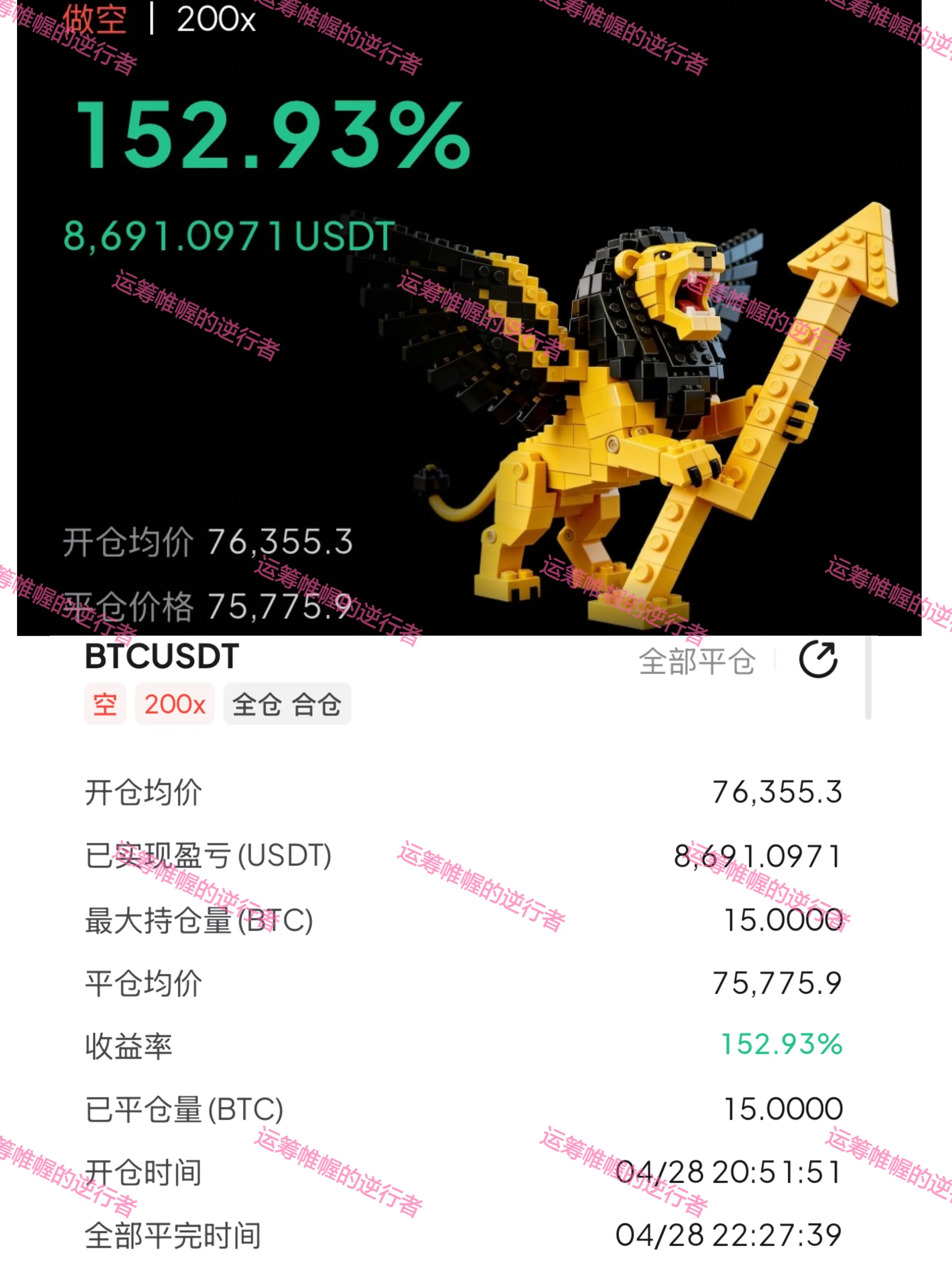
- 打賞
- 按讚
- 留言
- 轉發
- 分享
加載更多
加入 4000 萬人匯聚的頭部社群
⚡️ 與 4000 萬 人一起參與加密貨幣熱潮討論
💬 與喜愛的頭部創作者互動
👍 查看感興趣的內容
熱門話題
查看更多32.71萬 熱度
22.73萬 熱度
65.89萬 熱度
1275.06萬 熱度
1.39萬 熱度
最新消息
查看更多置頂
🔥 WCTC S8 全球交易賽正式開賽!
8,000,000 USDT 超級獎池解鎖開啟
🏆 團隊賽:上半場正式開啟,預報名階段 5,500+ 戰隊現已集結
交易量收益額雙重比拼,解鎖上半場 1,800,000 USDT 獎池
🏆 個人賽:現貨、合約、TradFi、ETF、閃兌、跟單齊上陣
全場交易量比拼,瓜分 2,000,000 USDT 獎池
🏆 王者 PK 賽:零門檻參與,實時匹配享受戰鬥快感
收益率即時 PK,瓜分 1,600,000 USDT 獎池
活動時間:2026 年 4 月 23 日 16:00:00 - 2026 年 5 月 20 日 15:59:59 UTC+8
⬇️ 立即參與:https://www.gate.com/competition/wctc-s8
#WCTCS810,000 USDT 悬賞,尋找跟單金牌星探!🕵️
挖掘頂級帶單員,贏取高額跟單體驗金!
立即參與:https://www.gate.com/campaigns/4624
🎁 三大活動,獎金疊滿:
1️⃣ 慧眼識英:發帖推薦帶單員,分享跟單體驗,抽 100 位送 30 USDT!
2️⃣ 強力應援:曬出你的跟單截圖,為大神打 Call,抽 120 位送 50 USDT!
3️⃣ 社交達人:同步至 X/Twitter,憑流量贏取 100 USDT!
📍 標籤: #跟单金牌星探 #GateCopyTrading
⏰ 限時: 4/22 16:00 - 5/10 16:00 (UTC+8)
詳情:https://www.gate.com/announcements/article/50848✍️ Gate 廣場「創作者認證激勵計劃」進行中!
我們歡迎優質創作者積極創作,申請認證
贏取豪華代幣獎池、Gate 精美周邊、流量曝光等超過 $10,000+ 豐厚獎勵!
立即報名 👉 https://www.gate.com/questionnaire/7159
📕 認證申請步驟:
1️⃣ App 首頁底部進入【廣場】 → 點擊右上角頭像進入個人主頁
2️⃣ 點擊頭像右下角【申請認證】進入認證頁面,等待審核
讓優質內容被更多人看到,一起共建創作者社區!
活動詳情:https://www.gate.com/announcements/article/47889