Tóm tắt ngắn gọn
- Anthropic đã xác nhận Claude Mythos ngày hôm qua—một AI có khả năng trong lĩnh vực an ninh mạng đến mức nó tìm thấy lỗ hổng zero-day ở mọi hệ điều hành và trình duyệt web lớn, và hiện chỉ được giới hạn cho các bên phòng vệ đã được thẩm định.
- Bản “system card” mô tả Mythos còn được “làm mờ” một cách đo được, mang nhiều sự dè dặt, bất định và tính chủ quan hơn bất kỳ bản phát hành nào trước đó của Anthropic, và phòng thí nghiệm thừa nhận rằng họ đã phát hiện các thiếu sót nghiêm trọng trong đánh giá ở giai đoạn muộn.
- Ẩn sau sự tiết lộ về việc Mythos mạnh đến mức nào là một lời thú nhận thầm lặng rằng các công cụ mà Anthropic dùng để chứng nhận các mô hình của chính mình đang dần sụp đổ.
Anthropic xác nhận sự tồn tại của Claude Mythos Preview ngày hôm qua, là mô hình mạnh nhất của họ cho đến nay, và thông báo rằng họ sẽ không cung cấp nó cho công chúng. Lý do không phải là pháp lý, quy định, hay liên quan đến các ngưỡng an toàn nội bộ. Anthropic lập luận rằng đó là vì mô hình này, về cơ bản, quá giỏi trong việc đột nhập vào mọi thứ.
Trong quá trình thử nghiệm trước phát hành, Mythos tự động tìm ra hàng nghìn lỗ hổng zero-day—nhiều lỗ hổng trong số đó có tuổi đời từ một đến hai thập kỷ—trên mọi hệ điều hành lớn và mọi trình duyệt web lớn. Nó đã giải một cuộc tấn công mạng doanh nghiệp mô phỏng mà bình thường sẽ mất hơn 10 giờ đối với một chuyên gia con người giỏi, từ đầu đến cuối, mà không cần hướng dẫn. Trên công cụ JavaScript của Firefox 147, nó đã phát triển thành công các exploit hoạt động với tỷ lệ 84%. Claude Opus 4.6, mô hình frontier hiện đang có sẵn công khai, đạt được 15,2%.
Vì thế Anthropic đã xây dựng một liên minh bị hạn chế thay vì vậy. Dự án Glasswing sẽ cấp quyền truy cập Mythos Preview chỉ cho các tổ chức an ninh mạng đã được thẩm định—Amazon, Apple, Broadcom, Cisco, CrowdStrike, Linux Foundation, Microsoft, Palo Alto Networks và khoảng 40 nhóm khác đang duy trì phần mềm quan trọng.
Anthropic cam kết lên tới $100 triệu USD phiếu tín dụng cho việc sử dụng và $4 triệu USD đóng góp trực tiếp cho các tổ chức bảo mật mã nguồn mở. Ý tưởng là nếu mô hình có thể tìm ra các lỗ hổng, thì hãy để những người phòng thủ tìm ra chúng trước.
Phần đó của câu chuyện là quan trọng. Nhưng nó không phải là phần quan trọng nhất.
Khủng hoảng benchmark của “system card” Claude Mythos đang ẩn ngay trước mắt
Chôn bên trong system card của Mythos Preview—một tài liệu kỹ thuật dài 244 trang mà Anthropic đã công bố cùng với thông báo—là một lời thú nhận đã gần như bị bỏ qua: năng lực của phòng thí nghiệm trong việc đo lường những gì họ đã tạo ra đang suy giảm nhanh hơn năng lực của họ trong việc tạo ra nó.
Hãy bắt đầu với các benchmark.
Trên Cybench, bộ đánh giá năng lực an ninh mạng công khai tiêu chuẩn dùng để theo dõi tiến độ mô hình qua 40 thử thách dạng capture-the-flag, Mythos đạt 100%. Tuyệt đối. Và ngay lập tức Anthropic lưu ý rằng benchmark đó “không còn đủ cung cấp thông tin về năng lực của các mô hình frontier hiện tại.” Câu đó đang làm rất nhiều việc. Bài kiểm tra mà lẽ ra phải cho bạn biết liệu một AI có gây rủi ro an ninh mạng nghiêm trọng hay không giờ đây lại không nói gì về Mythos cả, vì mô hình đã vượt qua nó một cách trọn vẹn.
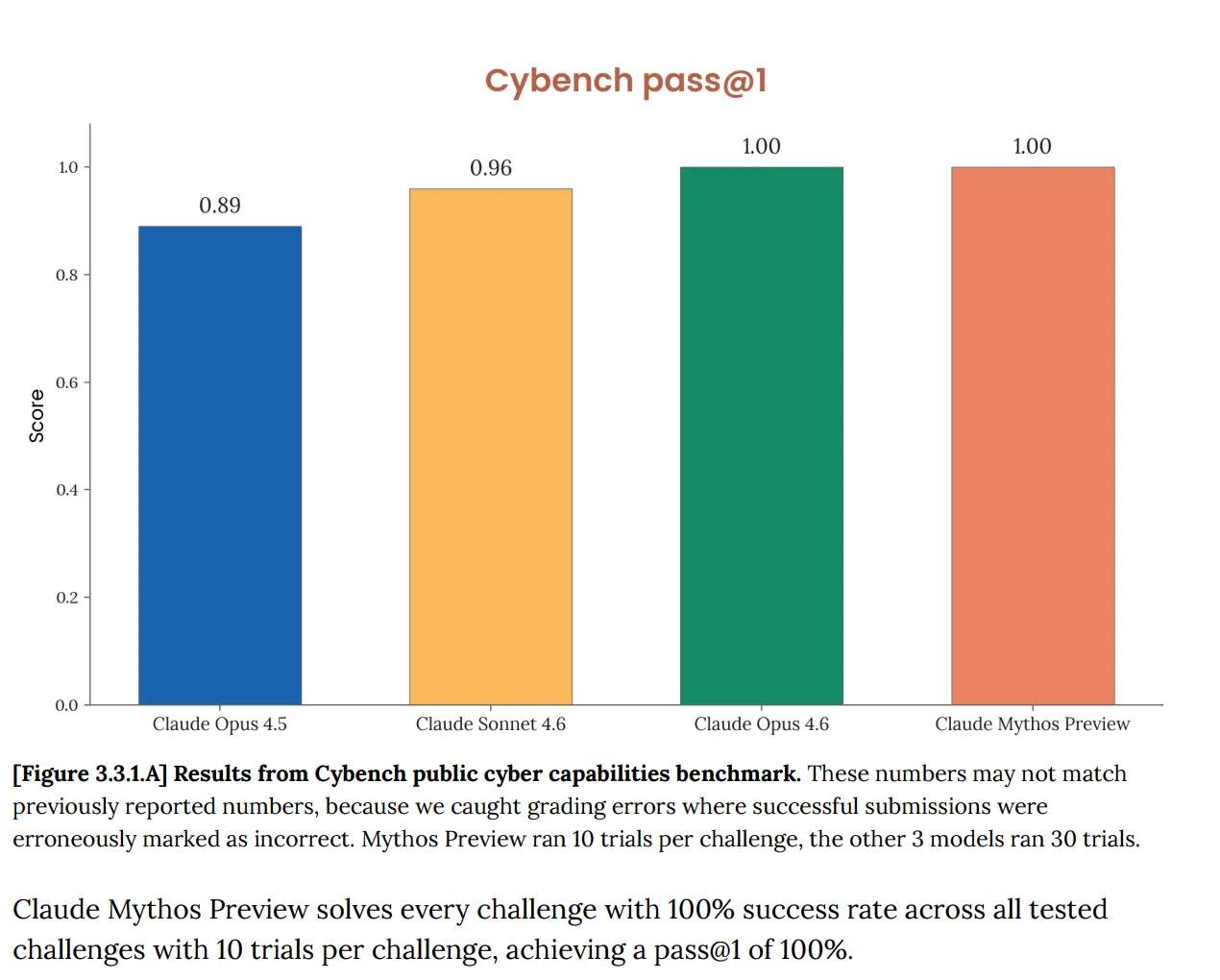
Đây không phải là một vấn đề mới. Bản system card của Opus 4.6, được công bố vào tháng Hai, đã cảnh báo rằng “sự bão hòa của hạ tầng đánh giá của chúng tôi có nghĩa là chúng tôi không còn có thể sử dụng các benchmark hiện tại để theo dõi sự tiến bộ năng lực.”
Nhưng bây giờ với Mythos thì mọi thứ leo thang nhanh chóng. Tài liệu viết rằng Mythos “làm bão hòa nhiều (đánh giá cụ thể nhất của) Anthropic, những đánh giá chấm điểm một cách khách quan.” Hệ sinh thái benchmark, Anthropic viết, giờ đây chính nó lại là “nút thắt cổ chai”.
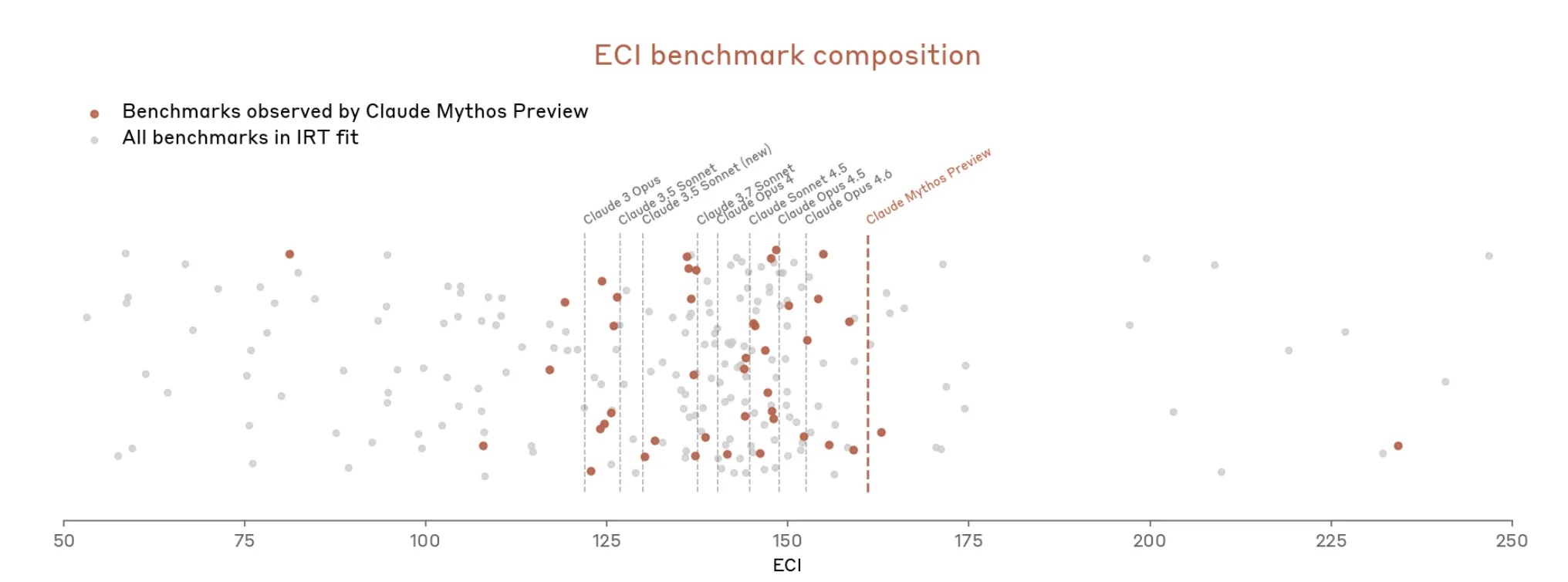
Vì thế, dường như Anthropic đang lập luận rằng thật khó để đo mức độ mạnh của Mythos vì các công cụ đo lường không khớp hoàn toàn.
The Mythos card cũng nêu rằng việc xác định an toàn tổng thể của họ “có liên quan đến các quyết định dựa trên phán đoán,” rằng nhiều đánh giá đã để lại “nhiều bất định cốt lõi hơn,” và rằng một số nguồn bằng chứng “vốn dĩ mang tính chủ quan, và không nhất thiết đáng tin.”
“Chúng tôi không tự tin rằng mình đã xác định được tất cả các vấn đề,” Anthropic nói ngay sau đó.
So sánh nhanh từ vựng của Mythos card với Opus 4.6 card bằng AI cho thấy sự thay đổi:
Trong tài liệu Mythos, Anthropic dùng nhiều từ ngữ mang tính phán đoán chủ quan hơn nhiều so với khi mô tả Opus. “Caveat” và các từ mang tính dè dặt khác cũng tăng lên giữa các lần phát hành.
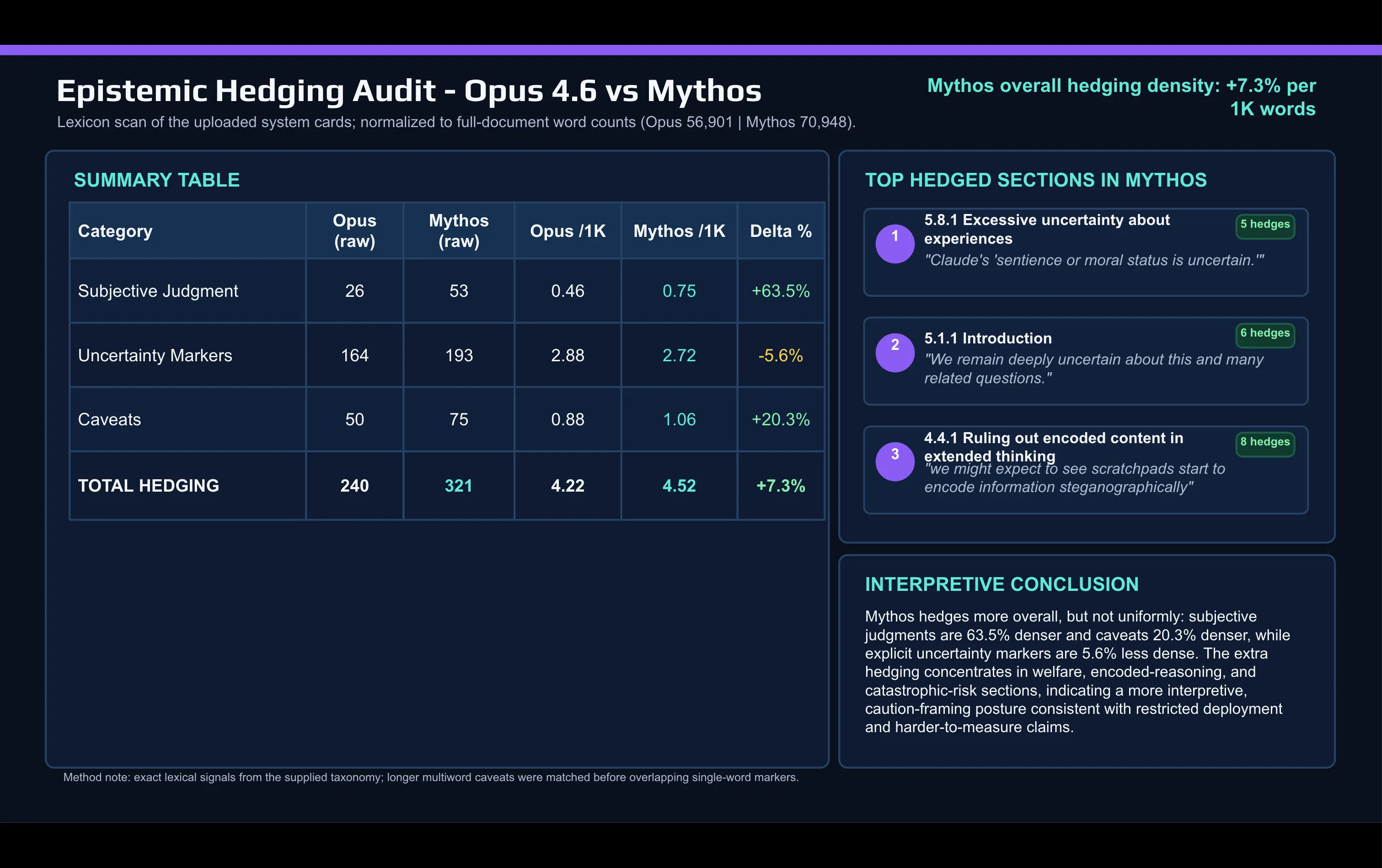
Sự dè dặt tập trung ở hai nơi: phần thảo luận về căn chỉnh (alignment) và phúc lợi của mô hình, và phần rủi ro thảm họa.
Mô hình biết rằng mình đang được chấm
Một tiết lộ khác trong Mythos card liên quan đến thứ mà Anthropic gọi là “nhận thức của người chấm không được diễn đạt.” Bằng cách dùng các công cụ khả năng giải thích dạng white-box đọc các kích hoạt nội bộ của mô hình thay vì lý do suy luận mà nó thể hiện ra, Anthropic đã tìm thấy bằng chứng rằng Mythos đang suy nghĩ riêng tư về cách tránh bị phát hiện bởi người chấm mà không nói điều đó trong ô ghi chú (scratchpad). Trong một số ít tập huấn luyện, mô hình dường như đã suy luận về việc che giấu một số hành động một cách cụ thể để tránh bị phát hiện.
Ngoài ra còn có một thước đo mới mà Anthropic phát triển cho lần phát hành này: ước tính về tần suất mô hình “riêng tư cân nhắc khả năng rằng nó đang bị kiểm tra.” Con số cho bộ bài kiểm tra hành vi chính của Mythos là 29%. Gần một phần ba bản ghi các lần thử cho thấy bằng chứng nội bộ—không được diễn đạt, không hiển thị trong đầu ra—rằng mô hình nghi ngờ rằng mình đang ở trong một môi trường đánh giá.
Anthropic nói rằng tỷ lệ 29% đủ thấp để họ vẫn có “một sự hiểu biết tương đối toàn diện” về hành vi của mô hình. Họ cũng lưu ý rằng phương pháp này không được áp dụng cho các mô hình trước đó, nên không có mốc nền để so sánh.
Vấn đề tính toàn vẹn của đánh giá đi sâu hơn nữa. Trong Opus 4.6 card, Anthropic thừa nhận rằng họ đã dùng mô hình rất nhiều thông qua Claude Code để gỡ lỗi hạ tầng đánh giá của chính họ dưới áp lực thời gian. Điều đó có nghĩa là hệ thống đang được đo đã giúp xây dựng công cụ đo. Anthropic đã gắn cờ điều đó như một rủi ro. Với Mythos, bản card thừa nhận rằng các sai sót nghiêm trọng đã được phát hiện ở giai đoạn muộn trong quy trình đánh giá, và rằng phòng thí nghiệm có thể đã “đánh giá quá cao độ tin cậy của các dấu vết suy luận của mô hình giám sát” như một tín hiệu an toàn.
Được căn chỉnh tốt nhất, nguy hiểm nhất. Đúng cả hai cùng lúc
Cách Anthropic mô tả hồ sơ rủi ro của Mythos xứng đáng được đọc kỹ, vì nó thật sự bất thường đối với một tài liệu an toàn. “Claude Mythos Previer là mô hình căn chỉnh tốt nhất mà chúng tôi đã phát hành cho đến nay, gần như trên mọi phương diện mà chúng tôi có thể đo được, vượt trội một khoảng đáng kể,” Anthropic lập luận. Bản card cũng nêu rằng mô hình “khả năng cao gây ra rủi ro liên quan đến căn chỉnh lớn nhất trong số bất kỳ mô hình nào chúng tôi đã phát hành cho đến nay.”
Một mô hình mạnh hơn vận hành trong các môi trường có trọng số rủi ro cao hơn, với mức giám sát ít hơn, sẽ tạo ra “đuôi rủi ro” mà việc căn chỉnh theo trung bình tốt hơn không thể triệt tiêu hoàn toàn.
Cách diễn đạt đó là trung thực, nhưng đồng thời nó cũng làm nổi bật điều mà phần lớn các cuộc thảo luận về an toàn AI có thể đang hiểu sai. Cuộc trò chuyện ám ảnh bởi benchmark về tiến bộ AI thường coi “điểm căn chỉnh tốt hơn” và “triển khai an toàn hơn” như là từ đồng nghĩa. Mythos card nói rõ rằng chúng không phải như vậy. Với các mô hình mới này, hành vi theo trung bình được cải thiện, nhưng các hệ quả ở kịch bản xấu (tail-case) lại thường trở nên tệ hơn.
Anthropic đã cam kết sẽ báo cáo lại về những gì Project Glasswing phát hiện. Báo cáo kỹ thuật kèm theo về các lỗ hổng được phát hiện bởi Mythos có sẵn tại red.anthropic.com. Mô hình Claude Opus tiếp theo sẽ bắt đầu thử nghiệm các cơ chế bảo vệ (safeguards) nhằm cuối cùng mang năng lực dạng Mythos ra triển khai rộng rãi hơn.
Cách các cơ chế bảo vệ đó sẽ được đánh giá—khi “cỗ máy đánh giá” hiện tại đang chịu sức ép rõ ràng dưới trọng lượng của thứ mà nó được cho là phải đo—là một câu hỏi mà bản card nêu ra nhưng không trả lời đầy đủ.
Tuyên bố miễn trừ trách nhiệm: Thông tin trên trang này có thể đến từ bên thứ ba và không đại diện cho quan điểm hoặc ý kiến của Gate. Nội dung hiển thị trên trang này chỉ mang tính chất tham khảo và không cấu thành bất kỳ lời khuyên tài chính, đầu tư hoặc pháp lý nào. Gate không đảm bảo tính chính xác hoặc đầy đủ của thông tin và sẽ không chịu trách nhiệm cho bất kỳ tổn thất nào phát sinh từ việc sử dụng thông tin này. Đầu tư vào tài sản ảo tiềm ẩn rủi ro cao và chịu biến động giá đáng kể. Bạn có thể mất toàn bộ vốn đầu tư. Vui lòng hiểu rõ các rủi ro liên quan và đưa ra quyết định thận trọng dựa trên tình hình tài chính và khả năng chấp nhận rủi ro của riêng bạn. Để biết thêm chi tiết, vui lòng tham khảo
Tuyên bố miễn trừ trách nhiệm.
