
يُعلن نظام الذاكرة المعتمد على الذكاء الاصطناعي MemPalace، الذي شاركت في تطويره ميلا جوفوفيتش، أنه حقق اختبارًا بدرجة كاملة ثم انتشر بسرعة، لكن المجتمع سرعان ما اتهمه بالغش في الاختبارات وتضليل البيانات. تكشف التجربة الفعلية عن تضخيم في النتائج ووجود أخطاء كثيرة، وقد اعترف الفريق بوجود عيوب وبدأ العمل على إصلاحها.
ميلا جوفوفيتش تبني “قصر ذاكرة” للذكاء الاصطناعي وتلفت انتباه الجمهور
بالأمس (4/7)، كان هناك خبر كبير في مجتمع الذكاء الاصطناعي: الممثلة الهوليوودية ميلا جوفوفيتش (Milla Jovovich)، المعروفة بأفلام مثل《Resident Evil》و《The Fifth Element》، تعاونت مع المطور Ben Sigman باستخدام Claude Code لتطوير نظام ذاكرة ذكاء اصطناعي مفتوح المصدر يُسمى “MemPalace”.
في لحظة، انتشرت فكرة “نجمة هوليوود عملاقة تعبر الحدود وتنجز مشروعًا بدرجة كاملة”، وحصل MemPalace حتى الآن على أكثر من 20 ألف نجمة على GitHub، لكن ذلك لم يلبث أن أثار شكوك مطوري المجتمع: هل هناك محتوى فعلي أم أنها مجرد مبالغة وتسويق؟
لنبدأ من الدافع وراء ظهور MemPalace. تذكر الوثائق الرسمية أن الهدف هو حل المشكلة المتمثلة في أن محتوى المحادثات، وعمليات اتخاذ القرار، ونقاشات البنية المعمارية في أنظمة الذكاء الاصطناعي الحالية غالبًا ما تختفي بعد انتهاء جلسات العمل، مما يؤدي إلى قيود تجعل جهود عدة أشهر تهبط إلى الصفر.
ولحل هذه المشكلة، يعتمد MemPalace بنية مكانية لتخزين الذاكرة، حيث يتم تصنيف المعلومات بشكل واضح إلى مناطق جناحية تمثل الأشخاص أو المشاريع، ضمن هياكل مختلفة مثل الممرات والغرف والدرج، مع الحفاظ على نص المحادثة الأصلي لإجراء استرجاع دلالي لاحق.
يصرح فريق التطوير بأن MemPalace حقق 100% في معيار تقييم الذاكرة طويلة الأمد LongMemEval، وأنه وصل إلى 96.6% من الدقة دون استدعاء أي واجهات برمجة تطبيقات خارجية، كما يمكن تشغيله بالكامل على الجهاز المحلي دون الحاجة للاشتراك في خدمات سحابية، ويأتي مزودًا بنظام لهجة AAAK يُقال إنه قادر على تحقيق ضغط بلا فقدان بمقدار 30 ضعفًا.
مصدر الصورة: GitHub نجمة أفلام هوليوود ميلا جوفوفيتش تبني قصر ذاكرة للذكاء الاصطناعي وتلفت الانتباه
الزملاء والمجتمع يشكون معًا، وطريقة الاختبار والمواد التسويقية مليئة بالعيوب
لكن نتيجة اختبار MemPalace التي تزعم أنها حققت درجة كاملة في LongMemEval سرعان ما جذبت شكوكًا من الزملاء.
وأشار PenfieldLabs، وهو أيضًا شركة تنتج أنظمة ذاكرة للذكاء الاصطناعي، إلى أن ادعاء MemPalace بتحقيق درجة كاملة في مجموعة بيانات LoCoMo أمر مستحيل رياضيًا، لأن الإجابات القياسية في مجموعة البيانات هذه تتضمن أصلًا 99 خطأ.
حلل PenfieldLabs ووجد أن نتيجة MemPalace بنسبة 100% ناتجة عن ضبط عدد عمليات الاسترجاع على 50 مرة، لكن أعلى عدد من مراحل الحوار في مجموعة بيانات الاختبار يبلغ 32 مرة فقط، وهذا يعني أن النظام يتجاوز مرحلة الاسترجاع مباشرةً ويُسلّم جميع البيانات لنموذج الذكاء الاصطناعي ليقرأها.
وبخصوص نتيجة 100% في LongMemEval، تم اكتشاف أن فريق التطوير ركّز على 3 مشكلات محددة حدث فيها خطأ ضمن التطوير، وكتب كود إصلاح مخصص، ما يثير شبهة الغش في مجموعة الاختبار.

مصدر الصورة: Reddit يشير PenfieldLabs من الزملاء إلى أن MemPalace تزعم أنها حققت درجة كاملة في مجموعة بيانات LoCoMo، وهو أمر مستحيل رياضيًا
تجربة مستخدمي GitHub الفعلية: اختبار الأساس فيه مكوّنات مضللة
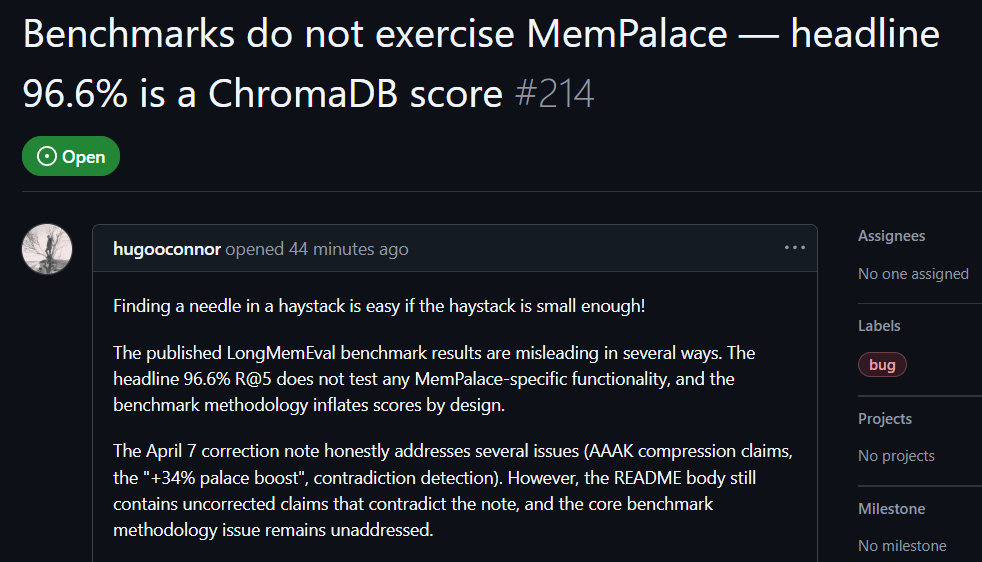
كتب المستخدم hugooconnor على GitHub بعد التجربة الفعلية أن MemPalace تدّعي أنها حققت نسبة دقة عالية تصل إلى 96.6% في الاسترجاع، لكنها في الواقع لم تستخدم إطلاقًا بنية “قصر الذاكرة” التي تروّج لها MemPalace. وذكر hugooconnor أن اختباراتهم كانت مجرد استدعاء الميزة الافتراضية لقاعدة البيانات الأساسية ChromaDB، دون أي تعامل مع منطق التصنيف الخاص بالمناطق الجناحية أو الغرف أو الأدراج التي يركز عليها المشروع.
بعد اختبار hugooconnor، تبين أنه عندما يتم تفعيل منطق التصنيف الخاص بهذه “قلاع/قصور الذاكرة” فعليًا، تتراجع نتائج الاسترجاع. فعلى سبيل المثال، في وضع الغرف تنخفض الدقة إلى 89.4%، وبعد تفعيل تقنية ضغط AAAK تنخفض الدقة أكثر إلى 84.2%، وكلاهما أقل من أداء قاعدة البيانات الافتراضي.
كما انتقد hugooconnor منهجية الاختبار. إذ صُمم بيئة اختبار MemPalace بشكل متعمد لتقليص نطاق الاسترجاع لكل سؤال إلى حوالي 50 مرحلة حوار، ما يجعل البحث عن الإجابات في مجموعة عينات صغيرة جدًا أمرًا سهلًا للغاية.
وعندما يتم توسيع النطاق إلى أكثر من 19,000 مرحلة حوار في سياقات واقعية، فإن دقة البحث التقليدي بالكلمات المفتاحية تنخفض بشدة إلى 30%، ما يوضح أن طريقة اختبار MemPalace الحالية تُخفي مشكلة البحث الحقيقية.
مصدر الصورة: GitHub مستخدمو GitHub يختبرون فعليًا، اختبار الأساس في MemPalace يحتوي على مكوّنات مضللة
وفي الوقت نفسه، رغم أن فريق التطوير نشر بيانًا للتصحيح، مع الاعتراف بأن تقنية AAAK تم التحقق منها بالفعل كضغط مع فقدان، وبأنه سيلتزم بتعديل وثائق الوصف وتصميم النظام وفقًا لانتقادات المجتمع الشديدة. لكن تبقى وثيقة الوصف الرئيسية للمشروع محتفظة بعدة ادعاءات مبالغ فيها لم يتم تصحيحها، بما في ذلك الادعاء بتحقيق ضغط بلا فقدان بمقدار 30 ضعفًا ورفع الاسترجاع بنسبة 34%، كما أن مخططات المقارنة مع المنافسين الآخرين تفتقر أيضًا تمامًا إلى مصادرها.
يواجه كود MemPalace الأصلي عدة أعطال/Bug
مع قيام المزيد والمزيد من المطورين بتحميل الاختبارات، ظهرت على منصة GitHub تقارير كثيرة عن الأخطاء المتعلقة بكود MemPalace الأصلي.
قام المستخدم cktang88 بإدراج عدة عيوب خطيرة، بما في ذلك أن أوامر الضغط لا تعمل ما يؤدي إلى تعطل النظام، وخطأ في منطق حساب عدد الكلمات في الملخص، وعدم دقة الإحصاءات الخاصة بحفر الغرف، بالإضافة إلى أن الخادم عند كل استدعاء يقوم بتحميل جميع بيانات التفسير إلى الذاكرة، مما يسبب مشكلة استهلاك موارد شديد.
ومن بين المشكلات الأخرى التي تم الإشارة إليها أيضًا: يقوم النظام بكتابة أسماء أفراد عائلة المطورين بشكل إجباري في ملف الإعدادات الافتراضي، وتوجد حدّ أقصى إجباري لعرض 10k سجل عند الاستعلام عن الحالة.
وبالنسبة لهذه المشكلات، بدأ مجتمع البرمجيات المفتوحة المصدر بالفعل في إجراء إصلاحات فعالة. قام المستخدم adv3nt3 بتقديم عدةطلباتإصلاح، بما في ذلك تصحيح بيانات إحصاءات الحفر، وإزالة أسماء أفراد العائلة الافتراضية، وتأخير وقت تهيئة المعرفة البيانية. كما اعترف فريق التطوير لاحقًا بهذه الأخطاء، وهو يعمل على حل مشكلات الكود تدريجيًا بالتعاون مع المجتمع.
ميلا جوفوفيتش Vibe Coding رائع، لكن أسلوب التسويق غير رائع
بالنسبة إلى مشروع MemPalace، توصل مستخدم Hacker News darkhanakh إلى نتيجة: يترك MemPalace انطباعًا يشبه OpenClaw، أي أنه يتم التلاعب يدويًا بنتائج اختبار الأساس (benchmark) لتبدو مثالية تمامًا، ثم يتم تغليفها وتسويقها على أنها إنجاز اختراق كبير.
ويرى أن التكنولوجيا الأساسية في MemPalace قد تكون مثيرة للاهتمام بالفعل، لكن مع وجود عيوب من هذا النوع في منهجية الاختبار، ومع ذلك ما يزال يتم الترويج لها قائلًا “أعلى درجة علنية على الإطلاق”، فهذا غير مناسب إلى حد كبير. “لكن، بخصوص أن ميلا جوفوفيتش تلعب Vibe Coding، أعتقد أنني ما زلت أجدها ممتعة جدًا.”
قراءة إضافية:
AI يكتب البرمجة ويحدث خلل! تطبيق “الصياد القانص” المعروض في محلات السوبرماركت للمنتجات ذات تاريخ انتهاء قريب يفجر مشكلة أمنية للبيانات، والجهاز GPS في المنزل مكشوف بالكامل
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.
